Predicting Restaurant Inspection Failures in Chicago
R
Machine Learning
Author
Richard Barad, Alex Jacobs
Published
December 20, 2023
Overview
This project was prepared as a final project for the MUSA-508: Public Policy Analytics at the University of Pennsylvania. The project uses machine learning techniques, specifically logistic regression to build a model to forecast the likelihood of restaurants in the city of Chicago passing their health inspections. The analysis relies heavily on data from the Chicago Open Data Portal and data from the U.S Census, American Community Survey dataset.
For an abbreviated high level summary of this analysis please watch our video which is viewable below. Continuing reading for additional information on the project context, motivation, exploratory data analysis, methodology, and results.
Context
The City of Chicago is the third most populated metropolitan area in the United States, boasting a robust culinary landscape with over 15,000 restaurants. Each of the city’s restaurants are subject to a recurring inspection, conducted under the purview of the Department of Public Health’s Division of Food Protection. The task of inspection falls on only 36 accredited sanitarians – leaving each with the responsibility of inspecting around 470 of the 15,000. This resource disparity presents a notable challenge to efficient and effective food safety monitoring.
Addressing resource disparity, Chicago’s solution includes leveraging data and partnering the city’s Department of Health with the Advanced Analytics Team housed in the Department of Innovation and Technology. Together, they developed a predictive model aimed at identifying restaurants most likely to have critical food safety violations. The existing model combines historical data, encompassing details from 100,000 past sanitation inspections – along with business characteristics and 311 complaints. The model enables inspectors to prioritize their inspections, concentrating on areas of the greatest risk to fail future food inspections.
The model’s implementation has yielded positive results harnessed by the city of Chicago. Food establishments with critical violations are now more likely to be identified earlier, leading to faster interventions and ultimately creating a increased quality along with availability of dining for Chicago residents. Adopting a more “science-based” initiative highlights the potential of data analytics to enhance public health and economic outcomes, particularly in city governments with limited resources.
Motivation
This project is based on a hypothetical scenario in which the City of Chicago has launched a program through its Department of Public Health and Office of Food Protection, allocating money to a Local Restaurant Improvement Fund. The city aims to appropriate funding resources to establishments facing elevated probability of non-compliance with food safety standards set by the Food Protection Division. Restaurants that receive this funding would be reminded of the importance of complying with public health guidelines and passing food inspections. As mentioned, on a yearly basis, all retail food establishments throughout Chicago are subject to recurring inspections. If a restaurant that has received funding is found to be in violation of public health guidelines, it would no longer be eligible for financial support through the program.
Building on the city’s previous work in predictive modeling, we have developed a supplementary forecasting tool tailored to predict a restaurant’s likelihood of failing food inspections during the upcoming year. Our model uses logistic regression to provide a one year forecast on the probability that a given restaurant will fail an inspection during the upcoming year. We train our model using restaurant inspection data for 2021, and divide the dataset into a training and test dataset. The training dataset is used to build the model and the test dataset is used to examine the accuracy of model predictions. This undertaking represents a departure from the conventional procedures common throughout the nation, in favor of a “science-based” methodology employed by the city. However, unlike the city’s current use of their predictive model, our model looks to specifically inform the deployment of funds contingent on passing health inspections. We harness predictive analytics to identify restaurants with an increased susceptibility to regulatory infractions. Our objective is clear: to optimize the impact of the allocated financial resources by strategically directing them towards establishments deemed most at risk of failing food inspections during the upcoming year.
The selected restaurants are set to receive financial support, and profit not only monetarily but benefit by engaging in an educational discourse on the importance of passing food inspections. The eligibility for funding hinges on adhering to food quality standards year after year, reinforcing the commitment to maintaining the restaurant’s quality. If, however, the establishment falls short of the city’s benchmarks, they face the halting of financial support of the city - a harsh reminder of the health standards set in place. Our proposed initiative, thus, unfolds as a structured and strategic intervention, positioning itself as a proactive mechanism for fostering restaurant quality and elevating the overall quality of restaurant offerings throughout the city of Chicago.
Application
To support the coordinated efforts regarding the restaurant improvement program informed by the predictive modeling, we propose a web-based application to share the model outputs. The key features we envision include a heat map showing where restaurants are predicted to fail inspections, a list of restaurant predictors along with corresponding information for each restaurant, a probability or confidence level toggle section, and supporting search and export features. The web-based application would also be translated into a smartphone format – one that may be more translatable to additional stakeholders outside of the city’s decision-makers relating to the Local Restaurant Improvement Fund. The smartphone format would contain the same elements as the browser-based application and will provide a clear direction concerning the funding program.
Upon thoroughly validating and testing our predictive model for desired outcomes, we intend to proceed with the implementation stage. This stage would involve operationalizing the web-based application with support from a software developer for a seamless and scalable launch. We will first run the model to develop predictions for the upcoming year and conduct a preliminary beta test with the city of Chicago to gather real-world feedback, and then prepare a full roll out strategy after initial testing is complete. Developing an effective rollout strategy is crucial for the app’s deployment, and we remain committed to continually refine the application based on valuable insights gathered through current inspection data used in our predictive forecasting model.
Import Data
Import Inspection Data
We begin building our predictive model by importing food inspection data from the city of Chicago, covering all records since our analysis focuses on historical failures. The provided information originates from assessments conducted on restaurants and food establishments in Chicago from January 1, 2010 to present. These inspections are carried out by personnel from the Chicago Department of Public Health’s Food Protection Program. Subsequently, the results are entered into a database for approval by a State of Illinois Licensed Environmental Health Practitioner. After importing the data on food inspections, we clean and standardize the business names along with the facility types. Our selectiveness ensures the predictive model will be built on the types of establishments (i.e: Restaurants, Bakeries, and Coffee Shops) we are trying to target for the Local Restaurant Improvement Fund.
Code
#Read data from city of Chicago on inspections - we need all data since we look at historical failuresdata <-read.socrata("https://data.cityofchicago.org/Health-Human-Services/Food-Inspections/4ijn-s7e5") %>%na.omit() %>%mutate(inspection_date =ymd(inspection_date),year =year(inspection_date),month =month(inspection_date),address =str_squish(address),facility_type =str_squish(str_to_title(facility_type)))#Clean up a bunch of messy facility names to be able to identify just facilities of (i.e: restaurants, cafes,and bakeries)data$facility_type[grepl("Bakery", data$facility_type)] <-"Bakery"data$facility_type[grepl("Coffee", data$facility_type)] <-"Coffee Shop"data$facility_type[grepl("Ice Cream", data$facility_type)] <-"Ice Cream Shop"data$facility_type[grepl("Deli", data$facility_type)] <-"Deli"data$facility_type[grepl("Taqueria", data$facility_type)] <-"Restaurant"data$facility_type[grepl("Hot Dog Station", data$facility_type)] <-"Restaurant"data$facility_type[grepl("Juice and Salad Bar", data$facility_type)] <-"Restaurant"data$facility_type[grepl("Restaurant", data$facility_type)] <-"Restaurant"#Standardize some names of businessesdata$dba_name[grepl("SEE THRU CHINESE", data$dba_name)] <-'SEE THRU CHINESE RESTAURANT'data$dba_name[grepl("JAMAICAN GATES", data$dba_name)] <-'JAMAICAN GATES'
Import Business License Data
We download business licenses from the Chicago Open Data Portal. These licenses are issued by the Department of Business Affairs and Consumer Protection in the City of Chicago, covering the period from 2002 to the present. Next, we proceed with importing and cleaning the data on business licenses. The data retrieval encompasses all licenses issued since 2010, the year our analysis starts given the limitation that our inspection data does not extend beyond the last 10 years. The business license data will be used to estimate the age of the restaurant.
Code
# Download Business Licenses From the Chicago Data Portalliscenses <-read.socrata("https://data.cityofchicago.org/resource/r5kz-chrr.json?$where=license_start_date%20between%20%272010-01-01T12:00:00%27%20and%20%272021-12-31T14:00:00%27")
Code
# Manual Cleaning Of Addressescorrections <-data.frame(bad =c("4623-4627 N BROADWAY 1 & 2","100 E WALTON ST 1 104","436-440 E 79TH ST","1733 W 87TH ST 1ST FLOOR","163 E WALTON ST 2ND F","5640 S UNIVERSITY AVE","5255 W MADISON ST 1 B","111 E 51ST ST 1ST`"),good =c("4623-4627 N BROADWAY", "100 E WALTON ST","436 - 440 E 79TH ST","1733 W 87TH ST","163 E WALTON ST","5640 S UNIVERSITY","5255 W MADISON ST","111 E 51ST ST 1ST"),stringsAsFactors =FALSE)liscenses$address <-match_vec(x=liscenses$address,corrections,from=1,to=2, quiet=TRUE)liscenses$address[grepl("47 W POLK ST", liscenses$address)] <-"47 W POLK ST"liscenses$address <-gsub("\\s*\\d+$", "", liscenses$address) #Remove any trailing numbersliscenses$address <-gsub("\\s*\\d+(ST)?$", "", liscenses$address) #Remove any trailing numbers which are followed by STliscenses$address <-gsub("\\s*\\d+(st)?$", "", liscenses$address) #Remove any trailing numbers which are followed by st#Standardize some business namesliscenses$doing_business_as_name[grepl("SEE THRU CHINESE", liscenses$doing_business_as_name)] <-'SEE THRU CHINESE RESTAURANT'liscenses$doing_business_as_name[grepl("THE NEW VALOIS REST", liscenses$doing_business_as_name)] <-'THE NEW VALOIS REST INC'liscenses$doing_business_as_name[grepl("CHICAGO MARRIOTT DOWNTOWN", liscenses$doing_business_as_name)] <-'CHICAGO DOWNTOWN MARRIOTT'liscenses$doing_business_as_name[grepl("STAR OF SIAM", liscenses$doing_business_as_name)] <-'STAR OF SIAM'liscenses$doing_business_as_name[grepl("EL CHILE RESTAURANT & PANCAKE HOUSE.", liscenses$doing_business_as_name)] <-'EL CHILE RESTAURANT & PANCAKE HOUSE'liscenses$doing_business_as_name[grepl("FRANCES' DELI & BRUNCHERY", liscenses$doing_business_as_name)] <-"FRANCES' REST & BRUNCHERY"
Read Boundary Datasets
We collect the spatial data for the neighborhoods and the overall city boundary of Chicago, preparing for our spatial analysis and upcoming visualizations. The boundaries of both the city and its neighborhoods are obtained from the Chicago Data Portal. The neighborhood boundaries layer is refined to include only the neighborhoods and geometry columns, and both the neighborhoods and the city boundary are transformed to a common spatial reference system for compatibility with the other datasets that will be used in our analysis.
We download census by block group for Chicago from the 2021 American Community Survey dataset for the following variables:
Total Households with Income below poverty line
Total Households
Total Population
Total White Population
Median Rent (USD)
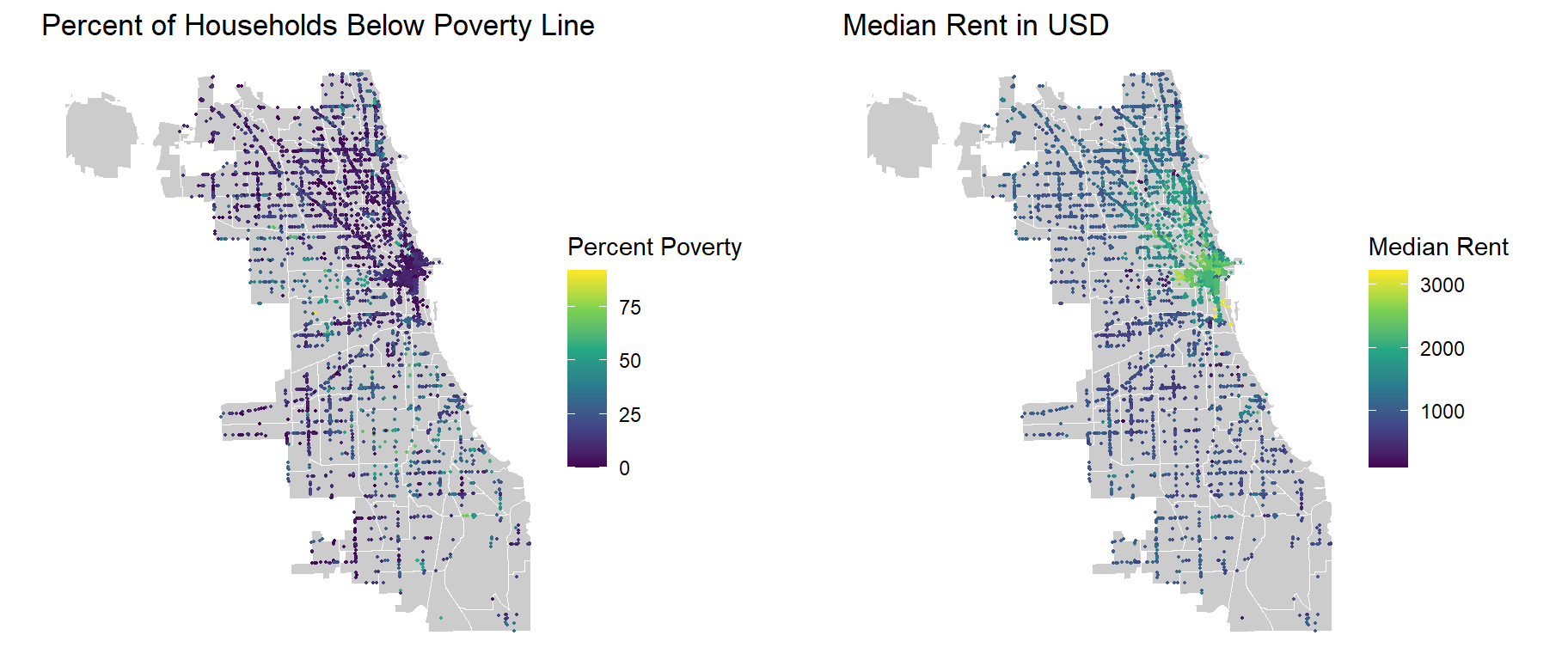
The dataset is cleaned and the geometries are transformed into the appropriate projected coordinate system. We use the household variables to calculate the percent of households in a census block that are below the poverty line. The percent poverty and median rent variables will be included as predictors in our model. Additionally, we calculate the percent of the population in a census tract that is white. This information is not included in our model, but will be used latter on to examine if model accuracy varies between majority white and majority non-white neighborhoods.
The first step in building the dataset we use to train our model involves filtering and cleaning the inspection data. This process involves projecting the restaurant data into the appropriate coordinate system and selecting just facilities that match the types of businesses eligible for funding through the restaurant improvement program. We also exclude the inspections conducted in the boundary housing the Chicago O’Hare International Airport and inspections of restaurants located inside Midway International Airport. We treat instances labeled as “Pass w/ Conditions” as equivalent to a regular “Pass,” and conduct a spatial join between the restaurants and neighborhood layer.
We build two clean datasets, one for 2021 and another for 2020. The 2021 will be used for building our model while the 2020 dataset will be used to engineer features about restaurant inspection pass rates in the previous year.
Code
filter <-c("Restaurant","Bakery","Tavern","Ice Cream Shop","Deli","Cafe","Coffee Shop","")#Function to clean inspection data, join to neighboorhoods and filter to just the year of interestclean_inspections <-function(df,y){ clean_df <- df %>%st_as_sf(coords =c("longitude", "latitude"), crs =4326, agr ="constant") %>%st_transform('ESRI:102271') %>% dplyr::filter(year == y & results !='Out of Business'& results !='No Entry'& results !='Not Ready'& results !='Business Not Located') %>% dplyr::filter(facility_type %in% filter) %>%mutate(results =ifelse(results=="Pass w/ Conditions","Pass",results),fail =ifelse(results=="Fail",1,0)) %>%st_join(.,neighboorhoods,predicate = st_intersects) %>%mutate(pri_neigh =ifelse(location =="(42.008536400868735, -87.91442843927047)","O'Hare",pri_neigh),pri_neigh =ifelse(location %in%c("(41.892249163400116, -87.60951804879336)","(41.89233780863412, -87.6040447589981)"),"Streeterville",pri_neigh)) %>% dplyr::filter(pri_neigh !="O'Hare") %>%# Remove Ohare Restaurants dplyr::filter(address !='5700 S CICERO AVE') # Remove Midway Restaurantsreturn(clean_df)}data_2021 <-clean_inspections(data,2021)data_2020 <-clean_inspections(data,2020)
Determine Restaurant Age
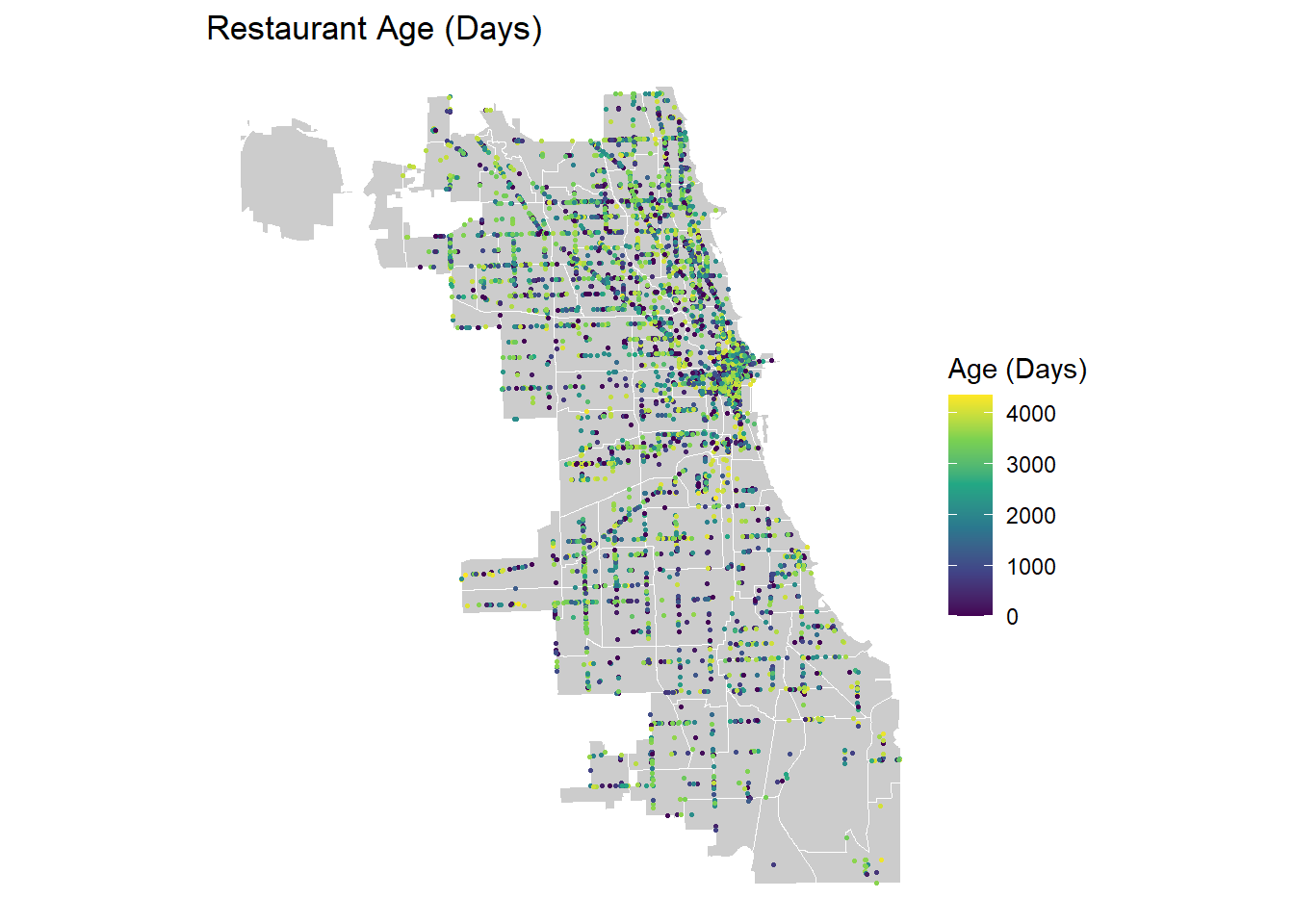
This code calculates the age of each business by referencing the date of its initial business license application. Specifically relating to retail establishments, it identifies the date when the license was first obtained. The minimum date is then joined back to the original license data and a subset of relevant columns is selected. The resulting age is estimated in days with a maximum age expected to be around 4,380 days (i.e: 365 days x 12 years).
To enhance accuracy, our code attempts various join methods to join the business license to the inspection data, as direct joining on the license id did not consistently yield matches. The time frame considered spans 12 years, reflecting the available license data from 2010 onward. This ensures that the analysis focuses on the relevant period up to the year 2021. For roughly 6% of 2021 inspections it was not possible to determine the age of the restaurant - we set the age of these restaurants equal to the city wide median. The map below shows the results of our age analysis for restaurants included in the 2021 inspection dataset.
Code
#For each for retail establishment determine date when a license was first obtainedliscense_min <- liscenses %>%group_by(doing_business_as_name,address) %>%summarize(min_date =min(license_start_date)) %>%arrange(min_date)#Join min date back to original licence data and select subset of columns liscenses_final <-left_join(liscenses, liscense_min , by =c('doing_business_as_name','address')) %>%select(license_id, account_number,legal_name,doing_business_as_name,address,site_number,min_date) %>%mutate(license_id =as.integer(license_id))#Join date business applied for first licence to 2021 inspection data - try to joins a variety of different ways since joining on licence number did not match allwaysdata_2021_2 <-left_join(data_2021,liscenses_final %>%select(license_id,min_date),by=join_by(license_==license_id)) %>%rename(min_date1 ='min_date') %>%left_join(.,liscense_min %>%select(doing_business_as_name,address,min_date),by=join_by(dba_name==doing_business_as_name,address==address),multiple='first') %>%rename(min_date2 ='min_date') %>%left_join(.,liscense_min %>%select(doing_business_as_name,address,min_date),by=join_by(aka_name==doing_business_as_name,address==address),multiple='first') %>%rename(min_date3 ='min_date') %>%mutate(min_date =pmin(min_date1, min_date2, min_date3, na.rm =TRUE), #Select lowest date where multiple joins workedage =as.integer(difftime(inspection_date, min_date, units ='days'))) %>%select(-min_date1,-min_date2,-min_date3)data_2021_2 <- data_2021_2 %>%mutate(age =ifelse(age<0,0,age),age =ifelse(is.na(age),median(age,na.rm=TRUE),age))ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = data_2021_2, aes(color = age), size =0.5) +scale_color_viridis_c(name ="Age (Days)") +labs(title ="Restaurant Age (Days)") +theme_void()
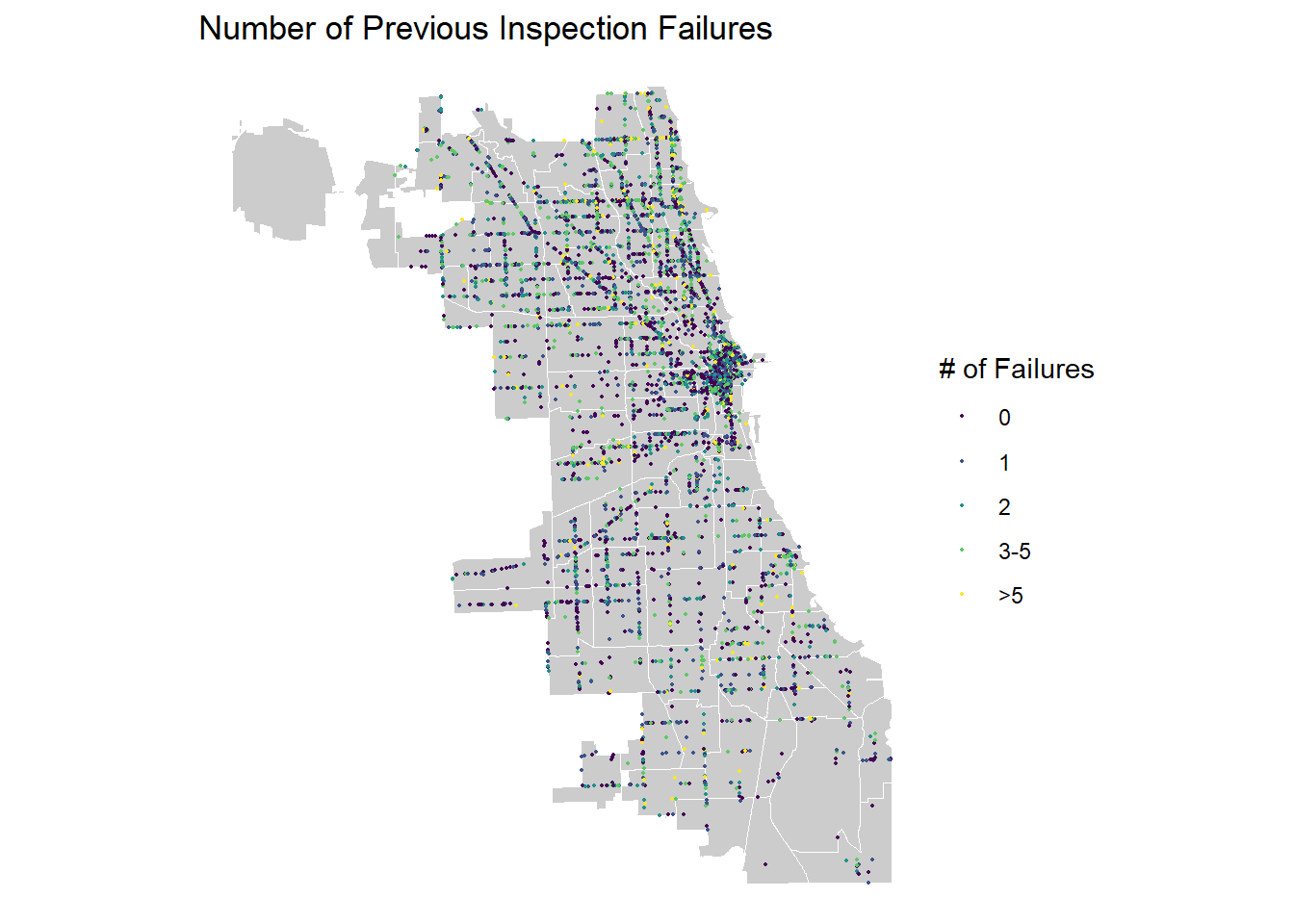
Estimate Number of Previous Violations
This code estimates the number of previous violations for each business within the dataset. It begins by filtering the data based on the condition that the year is earlier than 2021 and the outcome is defined as ‘Fail’. We then group the dataset by business name and address, and the violations are counted. The results are then joined to the 2021 inspection data after being renamed. The purpose of this code is to provide an overview of the historical violation records associated with each business, helping us understand the full compliance history throughout the city of Chicago.
We also use the age variable and the previous fail variable to calculate the number of failures per day open. This variable serves as an interaction term that considers both the age of the restaurant and the previous number of failures. The map below show the results of our previous inspection failure analysis for all restaurants in the 2021 inspection dataset.
Here, we integrate census data into the 2021 restaurant inspection dataset through a spatial join, associating each restaurant record with corresponding census block group information. A neighborhood level calculation is performed to determine the mean values for variables such as percent poverty, median rent, and percent non-white by neighborhood. Restaurants that lack a specific census block group association are assigned the mean value for the neighborhood the restaurant is located in. In the end, each restaurant entry is supported with the census socioeconomic information, producing a more detailed picture of demographic condition of the area surrounding each restaurant in our 2021 inspection dataset which will be used to build our model.
The maps below shows the census information for the restaurants in the 2021 inspection dataset.
This map illustrates the outcomes of food inspections in 2021, which will serve as the training data for our model. Notably, a concentration of inspection points is observed in and around the Loop, as well as along traffic corridors. The spatial distribution reveals clear clustering in areas where inspection failures are prevalent.
This map depicts the percent of restaurants that pass inspections. Restaurants in Garfield Park, New City and Chinatown have the highest fail rates in the city.
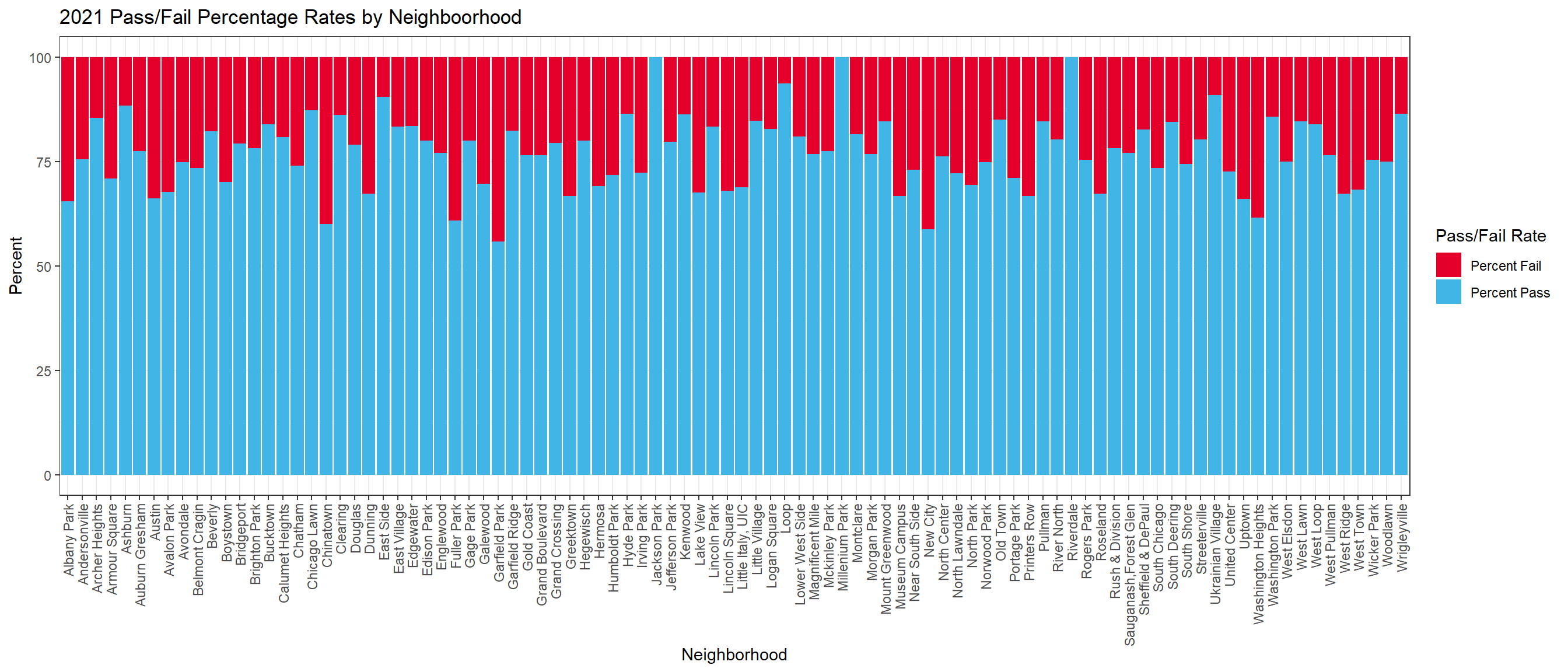
In the figure below, we have display a stacked bar plot to illustrate the pass and fail rates across various neighborhoods throughout Chicago. The x-axis denotes different neighborhoods, the y-axis represents rates, and the bars are stacked to visually depict the distribution of pass and fail rates of food inspections in 2021. Notably, Riverdale, Millennium Park, and Jackson Park emerge as the neighborhoods with the highest percentage of pass rates in Chicago, while Garfield Park, Navy City, and Chinatown exhibit the largest percentage of fail rates for food inspections. Note: The pass/fail rates may not be completely representative since they can be influenced by the number of restaurants, or the lack thereof in Chicago’s neighborhoods.
Code
neigh_summ %>%st_drop_geometry() %>%select(pri_neigh, pct_pass, pct_fail) %>%gather(pass, rate, -pri_neigh) %>%na.omit() %>%ggplot(aes(x = pri_neigh, y = rate, fill = pass)) +geom_bar(position ='stack', stat ='identity') +scale_fill_manual(values =c("pct_pass"="#41B6E6", "pct_fail"="#E4002B"),labels =c('Percent Fail','Percent Pass'),name='Pass/Fail Rate') +theme_bw() +theme(axis.text.x =element_text(angle =90, vjust =0.5, hjust =1)) +labs(title='2021 Pass/Fail Percentage Rates by Neighboorhood',x ="Neighborhood", y ="Percent", fill ="Pass/Fail")
Knearest Neighboor Analysis
311 Datasets
We obtain sanitation complaint and rodent-baiting data from the City of Chicago Open Data Portal for 2020. We use data for the previous year, because future implementation of the model will require using 311 data for the previous year since data for the current year will not yet be available. Duplicates are removed from the dataset and any data points without geometries are also removed. We also project the data into the appropriate projected coordinate system for Chicago.
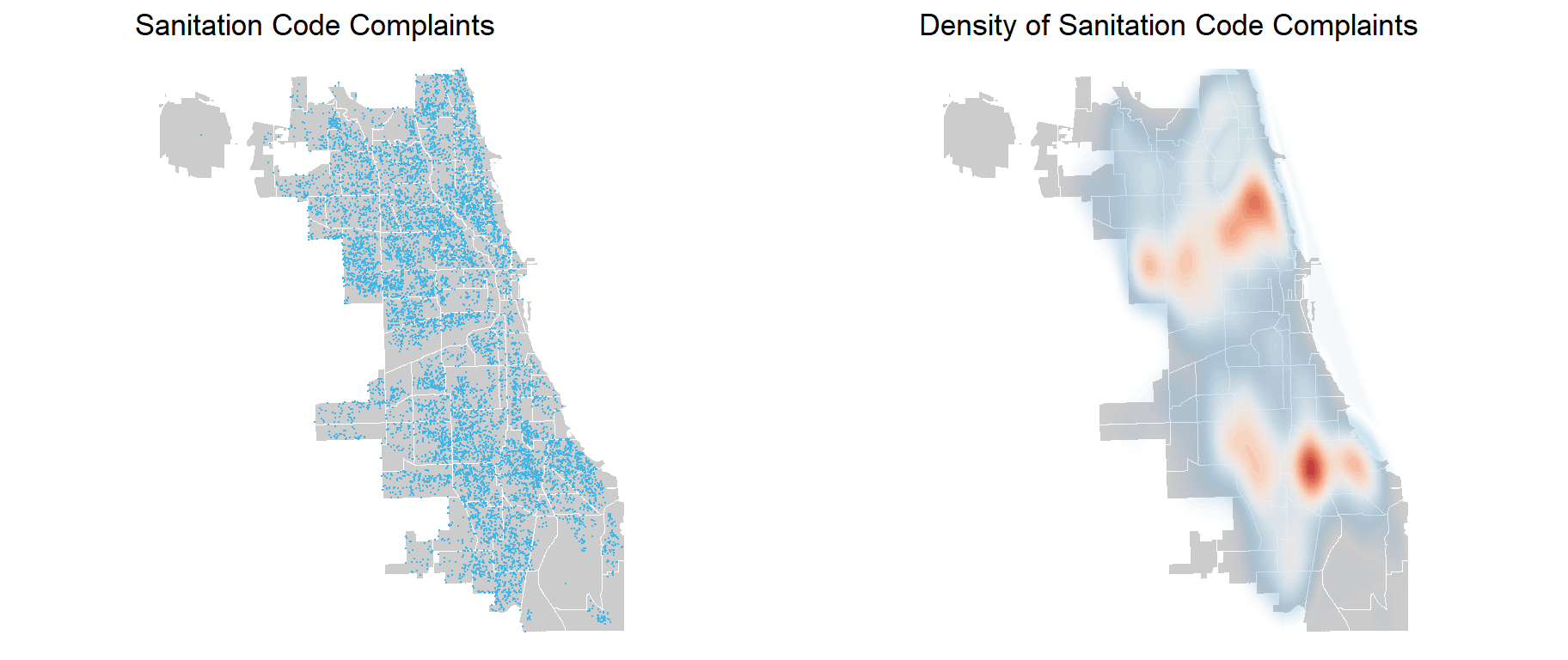
Below, we have created a two-panel mapping visualization illustrating both the point distribution and density of sanitation complaints. In the left panel, a point map is generated by overlaying sanitation service request data onto the boundaries of Chicago. The sanitation points are highlighted in blue, offering a spatial representation of sanitation code complaints across the city. The right visualization is a density map that shows the distribution of sanitation code complaints using kernel density. This map utilizes a color gradient to depict varying density levels, with cooler colors indicating lower densities and warmer colors signifying higher concentrations. This dual-panel visualization displays the spatial distribution and density patterns of sanitation code complaints in Chicago, highlighting hotspots in the northern areas of Lake View and North Center, and in the southern parts featuring Greater Grand Crossing and Chatham.
Code
grid.arrange(ncol =2,ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = sanitation2, colour ="#41B6E6", size =0.1, show.legend ="point") +labs(title ="Sanitation Code Complaints") +theme_void(),ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +stat_density2d(data =data.frame(st_coordinates(sanitation2)), aes(X, Y, fill = ..level.., alpha = ..level..),linewidth =0.01, bins =40, geom ='polygon') +scale_fill_distiller(palette ="RdBu") +scale_alpha(range =c(0.00, 0.35), guide =FALSE) +labs(title ="Density of Sanitation Code Complaints") +theme_void() +theme(legend.position ="none"))
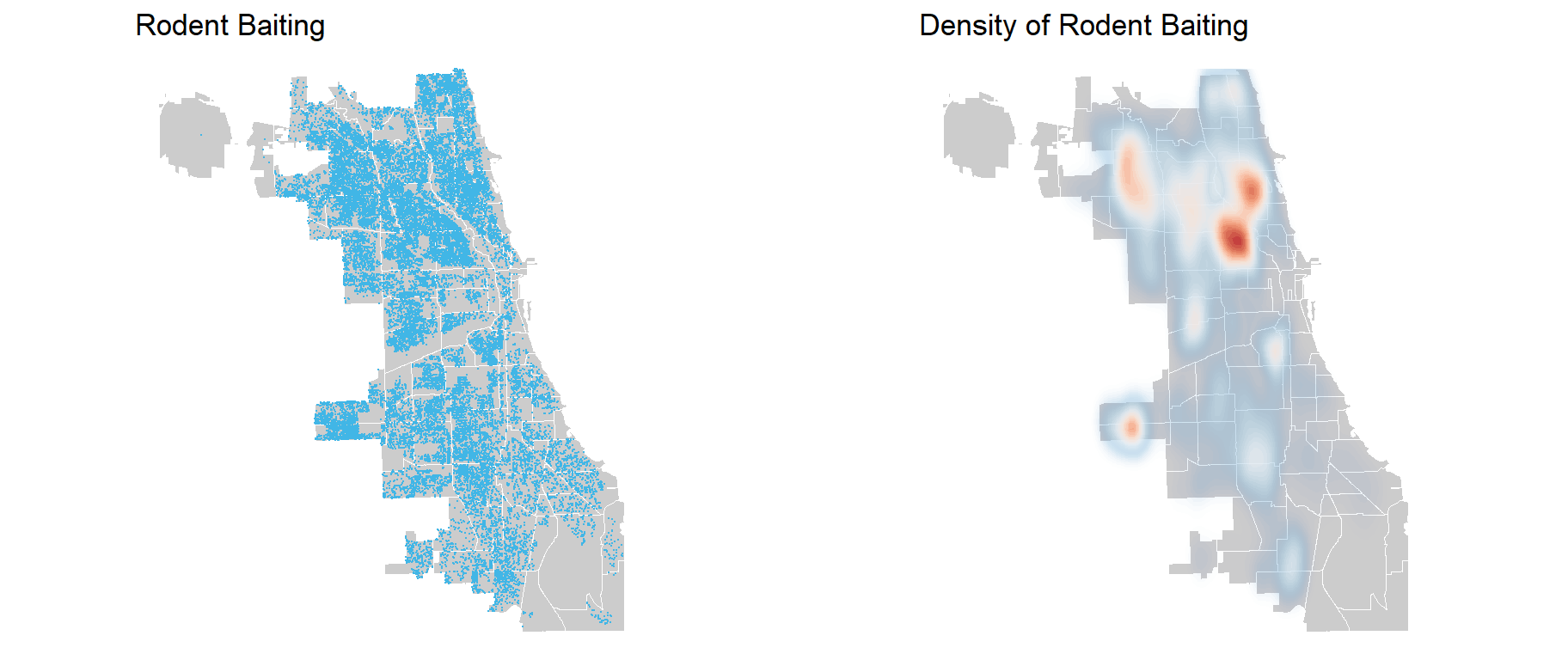
Similar to mapping sanitation complaints, we again present the following dual-panel mapping visualization focusing in on rodent baiting data. The rodent baiting points are highlighted in blue, providing a visual representation of rodent-related service requests across the city. The right visualization features a density map that illustrates the distribution of rodent baiting incidents using kernel density estimation. This map employs a color gradient to convey varying density levels, with cooler hues representing lower densities and warmer tones indicating higher concentrations. The two visualizations illustrate the spatial distribution and density pattern of rodent baiting incidents in Chicago with notable hotspots identified in Logan Square, Avondale, North Center, and Lincoln Square.
Code
grid.arrange(ncol=2,ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = rodents2, colour="#41B6E6", size=0.05, show.legend ="point") +labs(title="Rodent Baiting")+theme_void(),ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +stat_density2d(data =data.frame(st_coordinates(rodents2)), aes(X, Y, fill = ..level.., alpha = ..level..),linewidth =0.01, bins =40, geom ='polygon') +scale_fill_distiller(palette ="RdBu") +scale_alpha(range =c(0.00, 0.35), guide =FALSE) +labs(title ="Density of Rodent Baiting") +theme_void()+theme(legend.position ="none"))
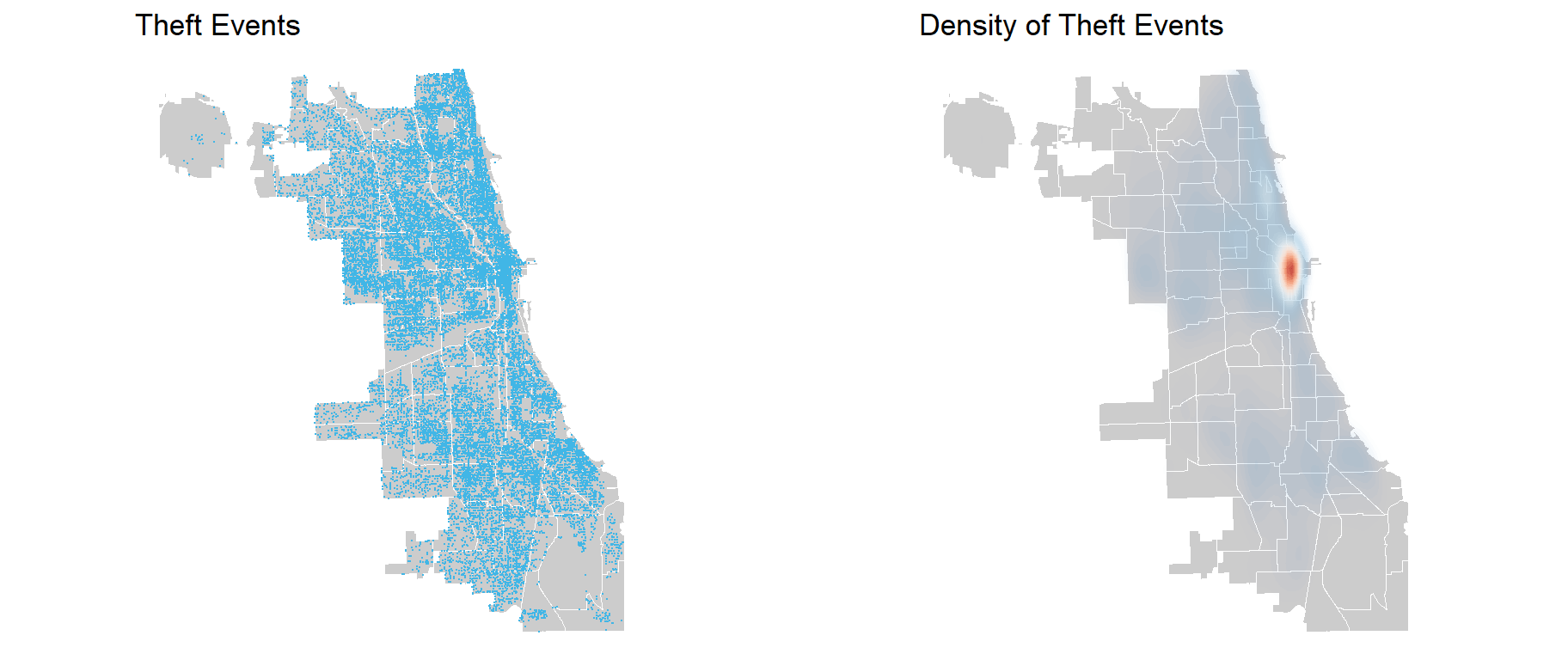
Theft Data
Thirdly, same as with sanitation complaints and rodent baiting, we have generated a dual-panel mapping visualization showcasing both point distribution and density for reported theft events. We utilize theft data obtained from the City of Chicago. We preprocessed the data to convert the ‘date’ column to a datetime format and extract the corresponding year, and filters out records with missing longitude or latitude values. The visualization methods used for both the point map and density maps align with those used in the previous panel visualizations. Upon analysis, we see a notable concentration of reported thefts in and around the Loop area.
Code
thefts <-read.socrata('https://data.cityofchicago.org/resource/qzdf-xmn8.json?primary_type=THEFT') %>%mutate(created_date =ymd_hms(date),year =year(date)) %>% dplyr::filter(!is.na(longitude)) %>% dplyr::filter(!is.na(latitude)) %>%st_as_sf(coords =c("longitude", "latitude"), crs =4326, agr ="constant") %>%st_transform('ESRI:102271')grid.arrange(ncol=2,ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = thefts, colour="#41B6E6", size=0.05, show.legend ="point") +labs(title="Theft Events") +theme_void(),ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +stat_density2d(data =data.frame(st_coordinates(thefts)), aes(X, Y, fill = ..level.., alpha = ..level..),linewidth =0.01, bins =40, geom ='polygon') +scale_fill_distiller(palette ="RdBu") +scale_alpha(range =c(0.00, 0.35), guide =FALSE) +labs(title ="Density of Theft Events") +theme_void()+theme(legend.position ="none"))
Temporal and Nearest Neighboor Analysis
In this code, we look at the percent of restaurants within 1km of each restaurant in the 2021 inspection dataset that failed an inspection in the year prior to our analysis (i.e: 2020). Building this variable, is based on principles of temporal lag, as we anticipate that areas that had a large percentage of restaurant failures in the previous year are likely to have a large percentage of restaurant failures again. Additionally, we also run a nearest neighbor analysis and calculate the average distance from each restaurant to the nearest 50 reported theft events, 50 sanitation complaints, and 50 rodent baiting events.
Code
# Producing a Nearest Neighbor Analysis Between the 2021 Inspection Data and 2020 Sanitation Complaints and 2020 Rodent Reportsbuffer <-st_buffer(data_2021_2,1000)rest_1000m <-st_join(buffer,data_2020 %>% dplyr::select('geometry','results')) %>%st_drop_geometry() %>%group_by(inspection_id,results.y) %>%tally() %>%ungroup() %>%spread(key=results.y,value=n) %>%select(-'<NA>') %>%replace(is.na(.), 0) %>%mutate(prev_year_pct_fail = Fail / (Pass + Fail)) %>%replace(is.na(.), 0) %>%select(inspection_id,prev_year_pct_fail)data_2021_2 <- data_2021_2 %>%mutate(rodents.nn =nn_function(st_coordinates(data_2021_2),st_coordinates(rodents2),k =50),sanitation.nn =nn_function(st_coordinates(data_2021_2),st_coordinates(sanitation2),k =50),thefts.nn =nn_function(st_coordinates(data_2021_2),st_coordinates(thefts),k =50)) %>%left_join(.,rest_1000m, by ='inspection_id') %>%left_join(.,neigh_summ %>%st_drop_geometry(), by ='pri_neigh')
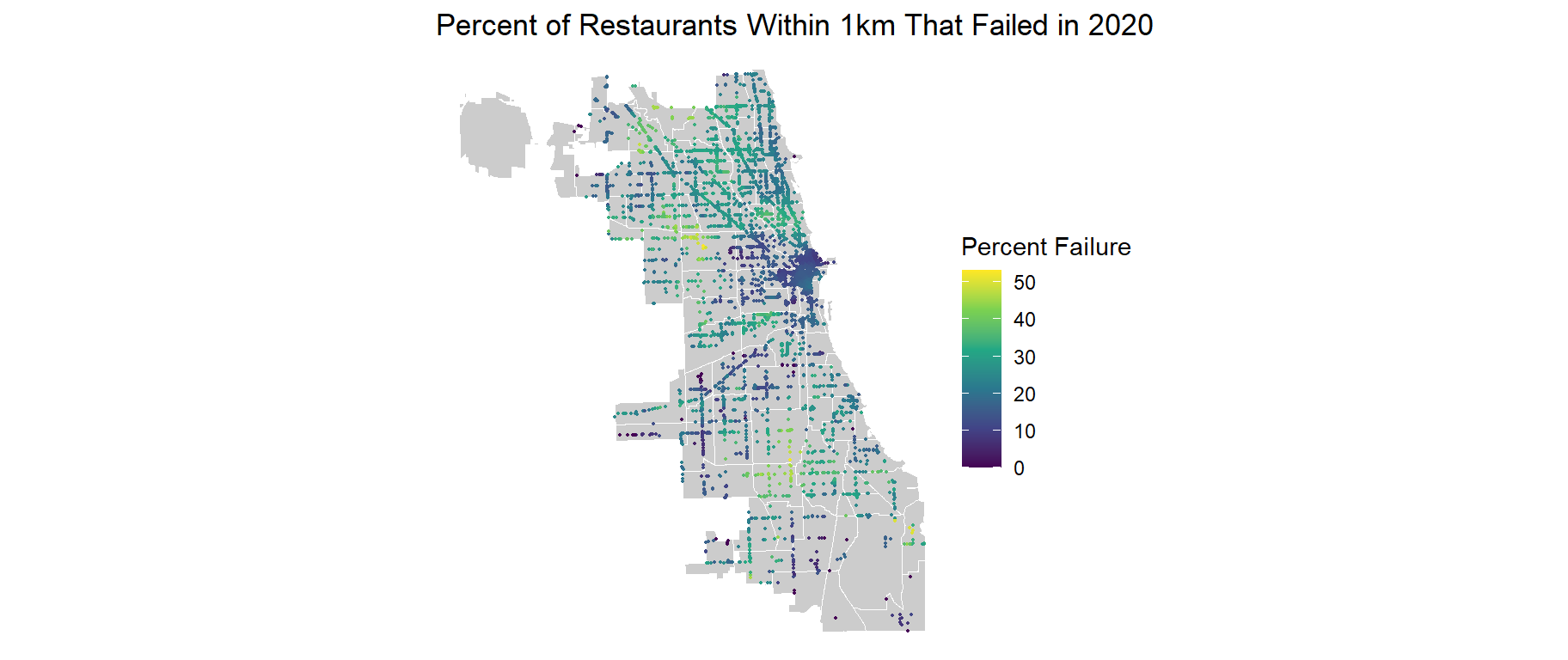
The map below shows the percent of restaurants within 1km of restaurants in the 2021 inspection dataset that failed inspection in the previous year. Restaurants in the area around the loop have a low percent failure rate. Restaurants in Auburn Gresham and Northwest Humbolt Park, and East Side have some of the highest percent failure rates for neighboring restaurants.
Code
ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = data_2021_2, aes(color = prev_year_pct_fail *100), size =0.3) +scale_color_viridis_c(name ="Percent Failure") +labs(title ="Percent of Restaurants Within 1km That Failed in 2020") +theme_void()
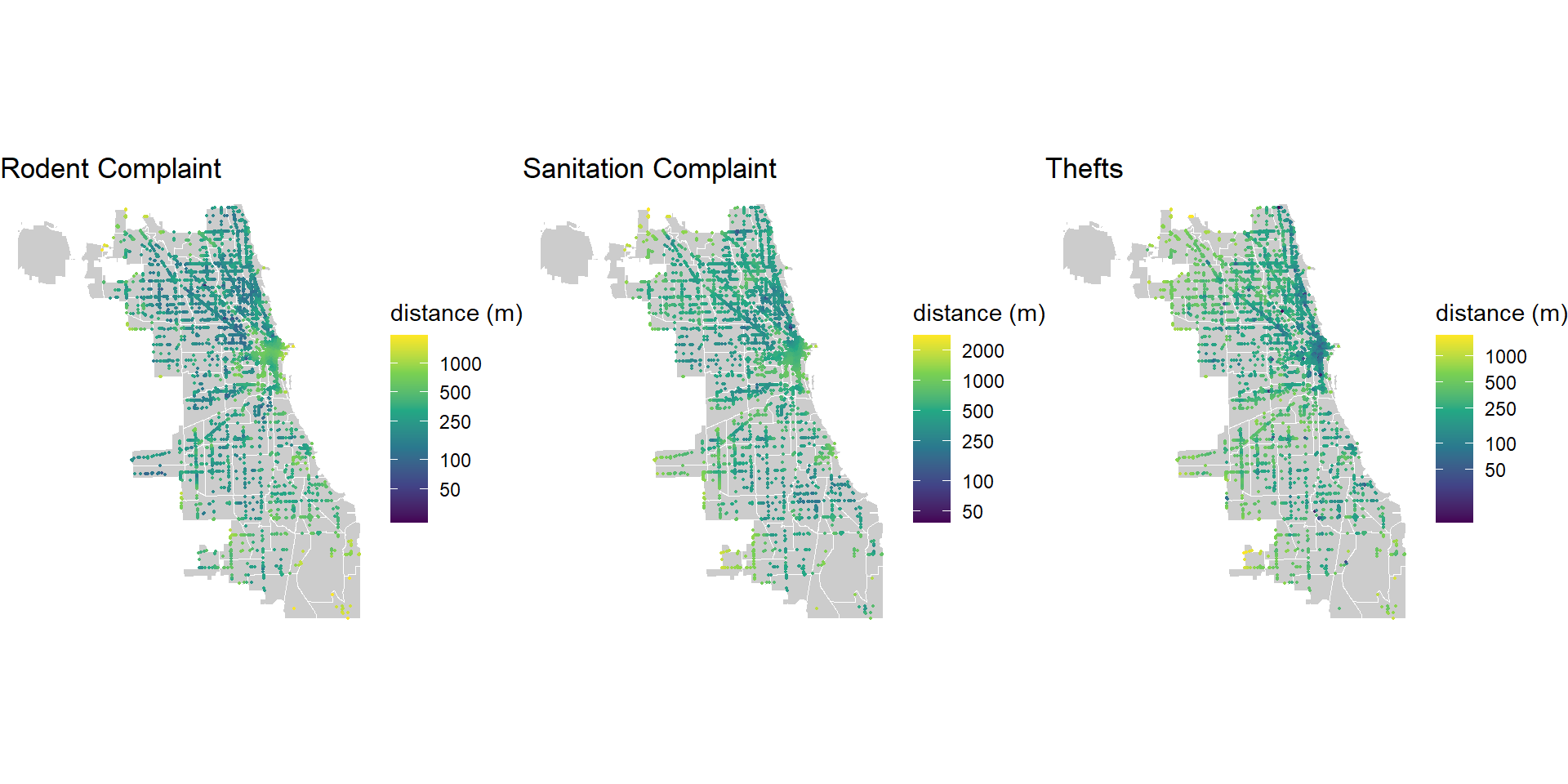
The maps below show the results of our k nearest neighbor analysis, the average distance from restaurants to the nearest 50 rodent baiting events, sanitation complaints, and theft events. Distance is calculated in meters. A log transformation is applied to the color gradient to account for the non-normal distribution of the data.
Code
my_breaks =c(50,100, 250, 500, 1000, 2000)grid.arrange(ncol=3,ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = data_2021_2, aes(color = rodents.nn), size =0.3) +scale_color_viridis_c(name ="distance (m)", trans ="log",breaks = my_breaks, labels = my_breaks)+labs(title ="Rodent Complaint") +theme_void(),ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = data_2021_2, aes(color = sanitation.nn), size =0.3) +scale_color_viridis_c(name ="distance (m)", trans ="log",breaks = my_breaks, labels = my_breaks)+labs(title ="Sanitation Complaint") +theme_void(),ggplot() +geom_sf(data = neighboorhoods, color ="white", fill ="grey80") +geom_sf(data = data_2021_2, aes(color = thefts.nn), size =0.3) +scale_color_viridis_c(name ="distance (m)", trans ="log",breaks = my_breaks, labels = my_breaks)+labs(title ="Thefts") +theme_void())
Explore Predictors
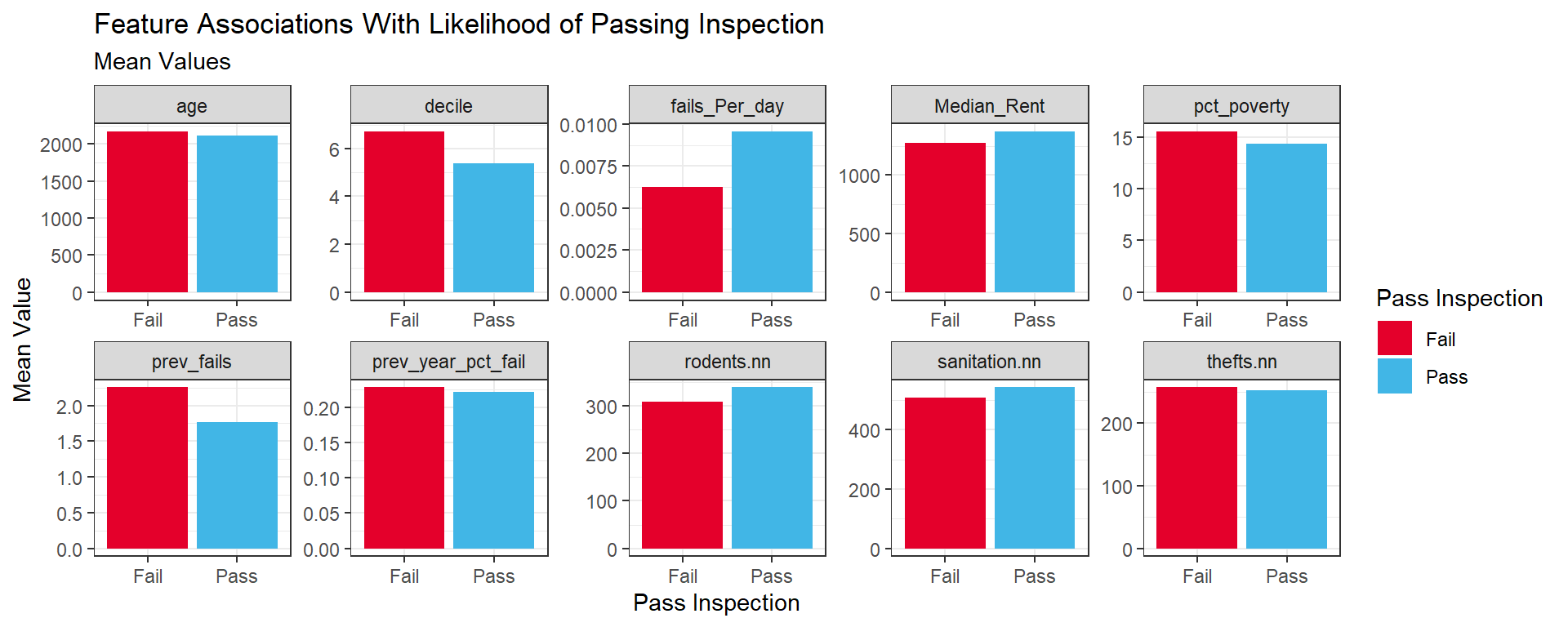
Having identified the predictors which we plan to use to predict restaurant failures we can explore the data to determine if there is a difference between the mean value for restaurants that fail inspection and restaurants that pass inspection. Based on the plots below, we can conclude that restaurants that fail tend to have a higher mean age, a lower mean number of previous fails per day open and a higher mean number of previous failures. Restaurants that fail also tend to be situated in census blocks with a lower mean median rent and higher mean percent of residents living in poverty. Additionally, Restaurants that fail also tend to have a lower mean average distance to the nearest 311 sanitation complaints and 311 rodent baiting events. The mean distance to the nearest 50 theft events is similar for restaurants that pass inspections and restaurants that fail inspections.
Code
# Look at the means for each continuous predictorquant_predictors <-c("rodents.nn","sanitation.nn","age","prev_fails","Median_Rent","pct_poverty","fails_Per_day","thefts.nn","prev_year_pct_fail","decile")data_2021_2_means <- data_2021_2 %>%st_drop_geometry() %>%group_by(results) %>%summarize_at(vars(quant_predictors),mean,na.rm=TRUE) data_2021_2_means %>%gather(key='variable',value='mean',-results) %>%ggplot(aes(x=results,y=mean,fill=results))+geom_bar(stat='identity')+facet_wrap(~variable,scales ="free",nrow=2)+scale_fill_manual(values=c("#E4002B","#41B6E6"),name='Pass Inspection')+labs(x="Pass Inspection", y="Mean Value", title ="Feature Associations With Likelihood of Passing Inspection", subtitle="Mean Values")+theme_bw()
The table below shows the mean value for each predictor for restaurants that failed inspection and restaurants that passed inspection. The table also includes the results of a series of t-tests. T-tests can be used to determine if the mean values are statistically different from each other. P-values that are less than 0.05 indicate that the mean value for restaurants that passed inspection and restaurants that failed are statistically different from each other. The difference in the mean is statistically significant for all predictors except for the age of the restaurant, the distance to nearest 50 reported theft events, and failures per day open.
Code
t_age <-t.test(data_2021_2$age~data_2021_2$fail)$p.valuet_decile <-t.test(data_2021_2$decile~data_2021_2$fail)$p.valuet_prev_fails <-t.test(data_2021_2$prev_fails~data_2021_2$fail)$p.valuet_pct_poverty <-t.test(data_2021_2$pct_poverty~data_2021_2$fail)$p.valuet_Median_Rent <-t.test(data_2021_2$Median_Rent~data_2021_2$fail)$p.valuet_rodents.nn <-t.test(data_2021_2$rodents.nn~data_2021_2$fail)$p.valuet_sanitation.nn <-t.test(data_2021_2$sanitation.nn~data_2021_2$fail)$p.valuet_fails_per_day <-t.test(data_2021_2$fails_Per_day~data_2021_2$fail)$p.valuet_thefts <-t.test(data_2021_2$thefts~data_2021_2$fail)$p.valuet_prev_year <-t.test(data_2021_2$prev_year_pct_fail~data_2021_2$fail)$p.valuep_values =c(t_age,t_decile,t_fails_per_day,t_Median_Rent,t_pct_poverty,t_prev_fails,t_prev_year,t_rodents.nn,t_sanitation.nn,t_thefts)data_2021_2_means %>%gather('variable','value',-results) %>%spread('results','value') %>%cbind(.,p_values, variables_text=c('Age (days open)','Neighboorhood Decile (1-10)','Fails per day open','Median Rent (USD)','Percent Poverty','Previous Number of Fails','Percent of Restaurants Failing in previous Year within 1k buffer','Average Distance distance to nearest 50 rodent complaints (meters)','Average Distance to nearest 50 sanitation complaints (meters)','Average distance to nearest 50 reported thefts (meters)')) %>% dplyr::select(variables_text,Fail,Pass,p_values) %>%kbl(col.names=c('Variables','Fail (Mean)','Pass (Mean)','t-test (p-value)')) %>%kable_minimal() %>%kable_styling(font_size =12)
Variables
Fail (Mean)
Pass (Mean)
t-test (p-value)
Age (days open)
2173.1507561
2118.2535315
0.1189924
Neighboorhood Decile (1-10)
6.7282609
5.3844909
0.0000000
Fails per day open
0.0062406
0.0095771
0.2552960
Median Rent (USD)
1276.1614354
1376.5984488
0.0000000
Percent Poverty
15.5999453
14.3846861
0.0002412
Previous Number of Fails
2.2514178
1.7675103
0.0000000
Percent of Restaurants Failing in previous Year within 1k buffer
0.2284077
0.2223942
0.0061856
Average Distance distance to nearest 50 rodent complaints (meters)
309.3686868
339.2065996
0.0000000
Average Distance to nearest 50 sanitation complaints (meters)
509.4038871
542.6824018
0.0000000
Average distance to nearest 50 reported thefts (meters)
257.0333475
252.7101892
0.2602631
Multicollinearity checks
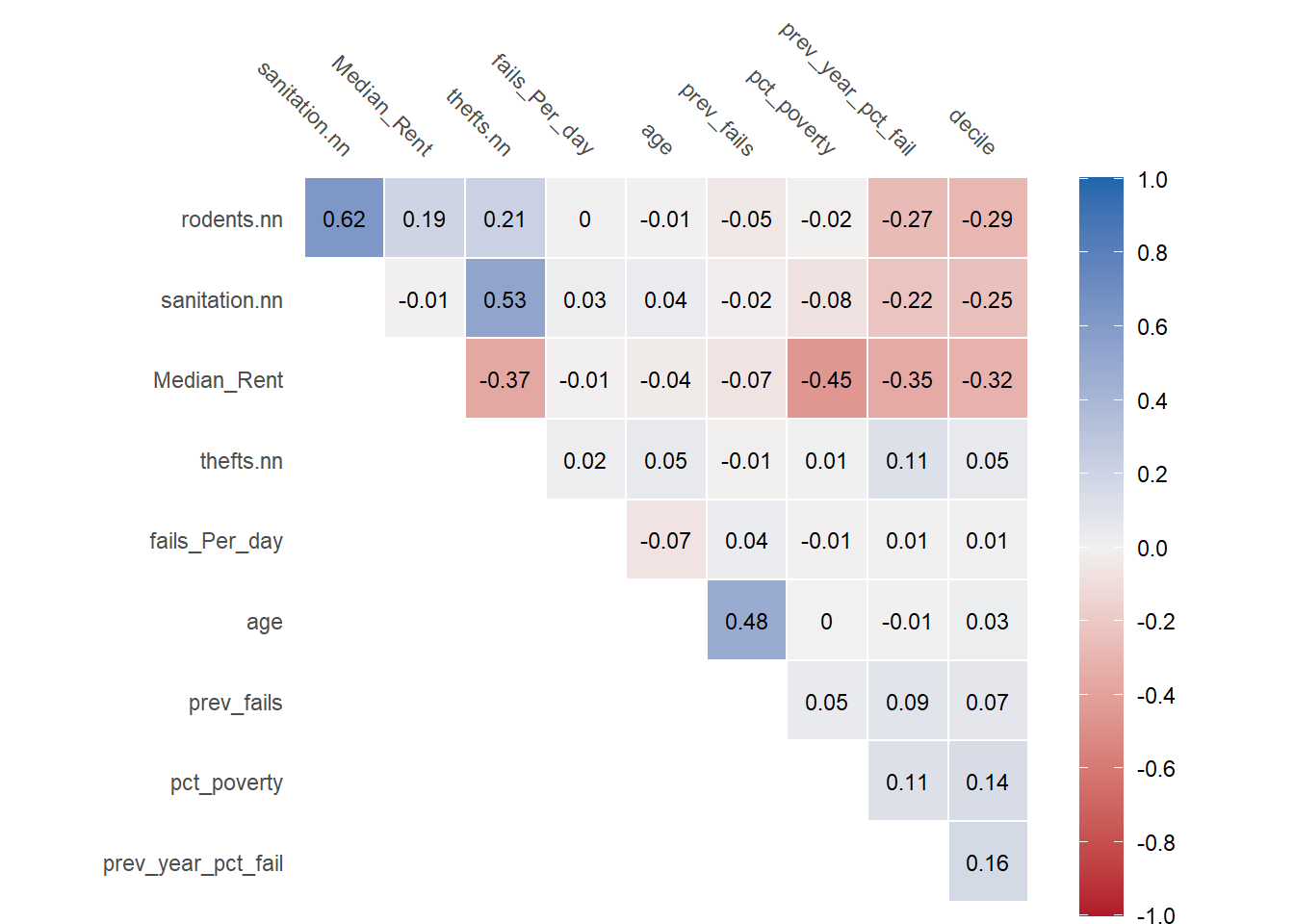
Next, we examine the correlation matrix for the predictors in our model. Checking the correlation matrix is an important step because it allows us to determine if there is any severe multicollinearity between any of predictors. A logistic regression should not include variables that exhibit multicollinearity. We consider variables to be severely multicollinear if the r value is greater than 0.7 or less than -0.7. Based on the correlation matrix below we can conclude that is no severe multicollinerity between our predictors and they can all be safely included in our predictive model.
We now proceed to the modelling stage of our analysis. We develop three different models in order to compare the accuracy of models developed using different predictors.
Split into Training and Test Data
The dataset containing restaurants inspection results for 2021 and our feature engineered predictors is split into two parts. Seventy percent of the data is put into the training dataset which will be used to train the logistic regression models. Thirty percent of the data is placed in the test dataset. We will predict the inspection result for each of the data points in the test dataset and compare the predicted outcome to the actual outcomes to assess the model accuracy.
Code
# Split Data Into 70:30 Training Dataset and Test Dataset# Taken From Housing Subsidy Assignment, 6.3.1 In Bookset.seed(3456)trainIndex <-createDataPartition(y =paste(data_2021_2$pri_neigh, data_2021_2$fail), p = .70,list =FALSE,times =1)train <- data_2021_2[ trainIndex,]test <- data_2021_2[-trainIndex,]
Build Models
Model 1
Our first model includes the following predictors: Age of restaurant, previous number of fails, fails per day open, Median Rent of census block, percent poverty of census block, and the theft, rodent, and sanitation nearest neighbor variables. The table below shows the Beta Coefficient and p-value for each of the predictors in the model. Examining the p-value can help provide a sense of the predictive power of the variable. We decide to retain all variables because all variables have a p-value that is lower than 0.3. While some of the p-values are not statistically significant they do appear to be adding some predictive power to the model.
In our second model, we include all the same variables as model one. We also add the variable that indicates that percent of restaurants within 1 kilometer that failed inspections in the previous year as a predictor (i.e: prev_year_pct_fail). The Beta Coefficients and p-values for Model 2 are shown below. The prev_year_pct_fail has a low p-value so we decide to retain it in model 3.
Model three includes all the same predictors as model two but we also include the decile associated with the failure rate of the neighborhood the restaurant is located in. The predictive power of the decile variable is very high as noted by the high beta coefficient and the p-value which is close to 0.
We make predictions using all three logistic models. The result is a prediction using each of the models for each of the restaurants in the test dataset.
Each of the logistic regression models outputs a probability indicting the likelihood that a restaurant will pass an inspection. Probabilities are produced for each restaurant in the test dataset for each model.
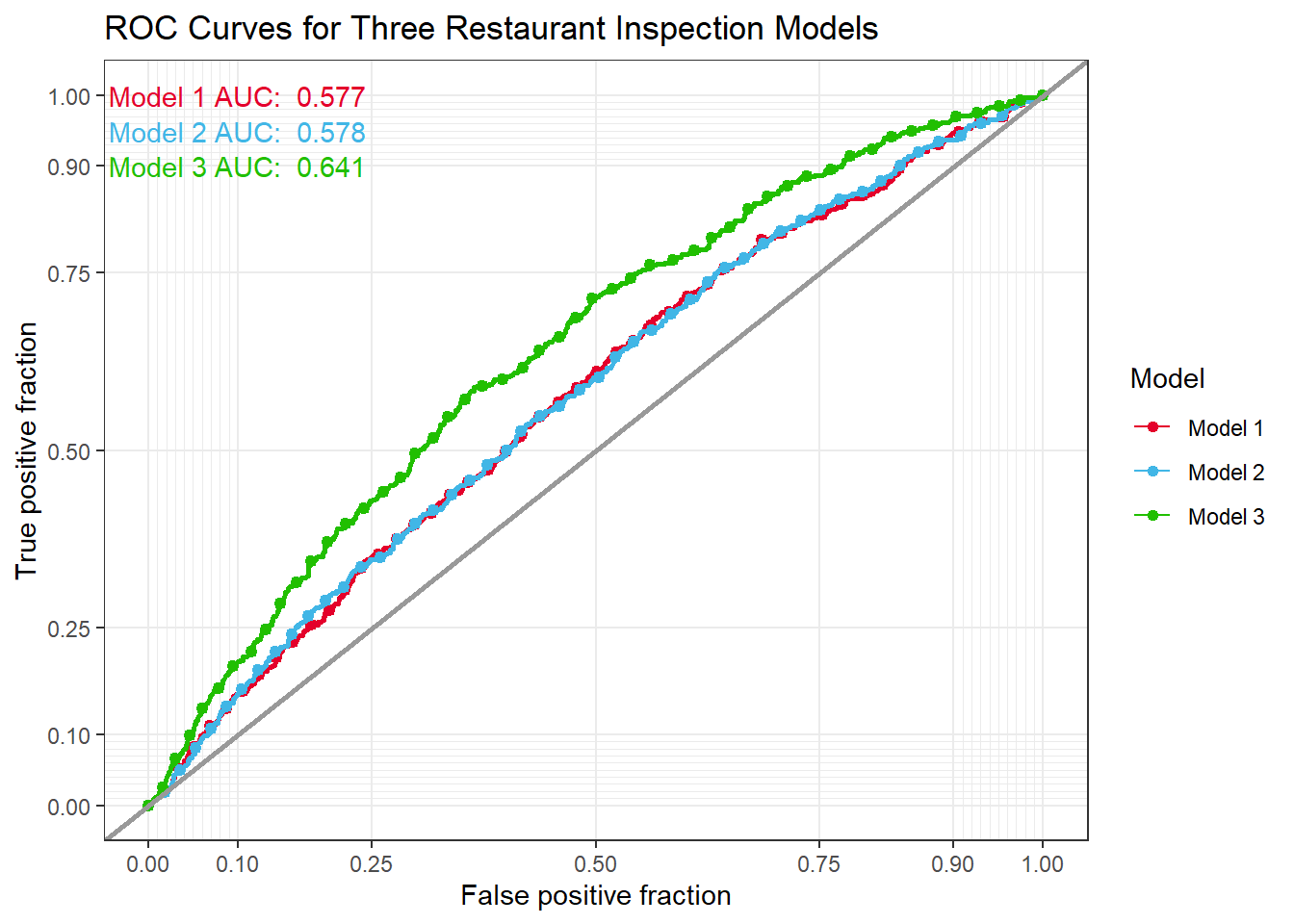
We will use a receiver operating characteristic curve (ROC) to assess the overall fit of each model. In our ROC curves we plot the false positive fraction (i.e: percent of Passes incorrectly predicted) and True positive fraction (i.e: percent of passes correctly predicted) at fifty different thresholds. The ROC curves help show the trade offs in a logistic regression analysis. If we select a lower thresholds, the model will correctly predict more restaurant failures (i.e: the true positive fraction will be high). However, when a low threshold is used the model will also likely incorrectly predict many restaurants as failing inspections that actually would pass inspection (i.e: the false positive rate will also be high).
All three models are a step above selecting restaurants at random. The grey line shown below shows what an ROC curve would look like if restaurants were selected randomly for the restaurant improvement program.
A useful way to compare the fit of the different logistic regression models is to calculate the Area Under (AUC) metric for each of the ROC curves. ROC curves that have a higher AUC have a better fit. The AUC values are visible in top left hand corner of the ROC plot. Model three has the highest AUC of the three models. Moving forward, we will only present results for Model 3.
Code
auc1 <-round(pROC::auc(testProbs$Outcome,testProbs$probs1),3)auc2 <-round(pROC::auc(testProbs$Outcome,testProbs$probs2),3)auc3 <-round(pROC::auc(testProbs$Outcome,testProbs$probs3),3)ggplot(testProbs) +geom_roc(aes(d =as.numeric(Outcome), m = probs1, colour ="Model 1"),n.cuts =50, labels =FALSE) +geom_roc(aes(d =as.numeric(Outcome), m = probs2, colour ="Model 2"),n.cuts =50, labels =FALSE) +geom_roc(aes(d =as.numeric(Outcome), m = probs3, colour ="Model 3"),n.cuts =50, labels =FALSE) +annotate("text", x =0.1, y =1, label=paste("Model 1 AUC: ",as.character(auc1)),color='#E4002B')+annotate("text", x =0.1, y =0.95, label=paste("Model 2 AUC: ",as.character(auc2)),color='#41B6E6')+annotate("text", x =0.1, y =0.90, label=paste("Model 3 AUC: ",as.character(auc3)),color='#21bf01')+scale_color_manual(values =c("#E4002B","#41B6E6","#21bf01"),name="Model")+style_roc(theme = theme_grey) +geom_abline(slope =1, intercept =0, size =1, color ='grey60') +labs(title ="ROC Curves for Three Restaurant Inspection Models")+theme_bw()
Model Results
Predicted Probability Density
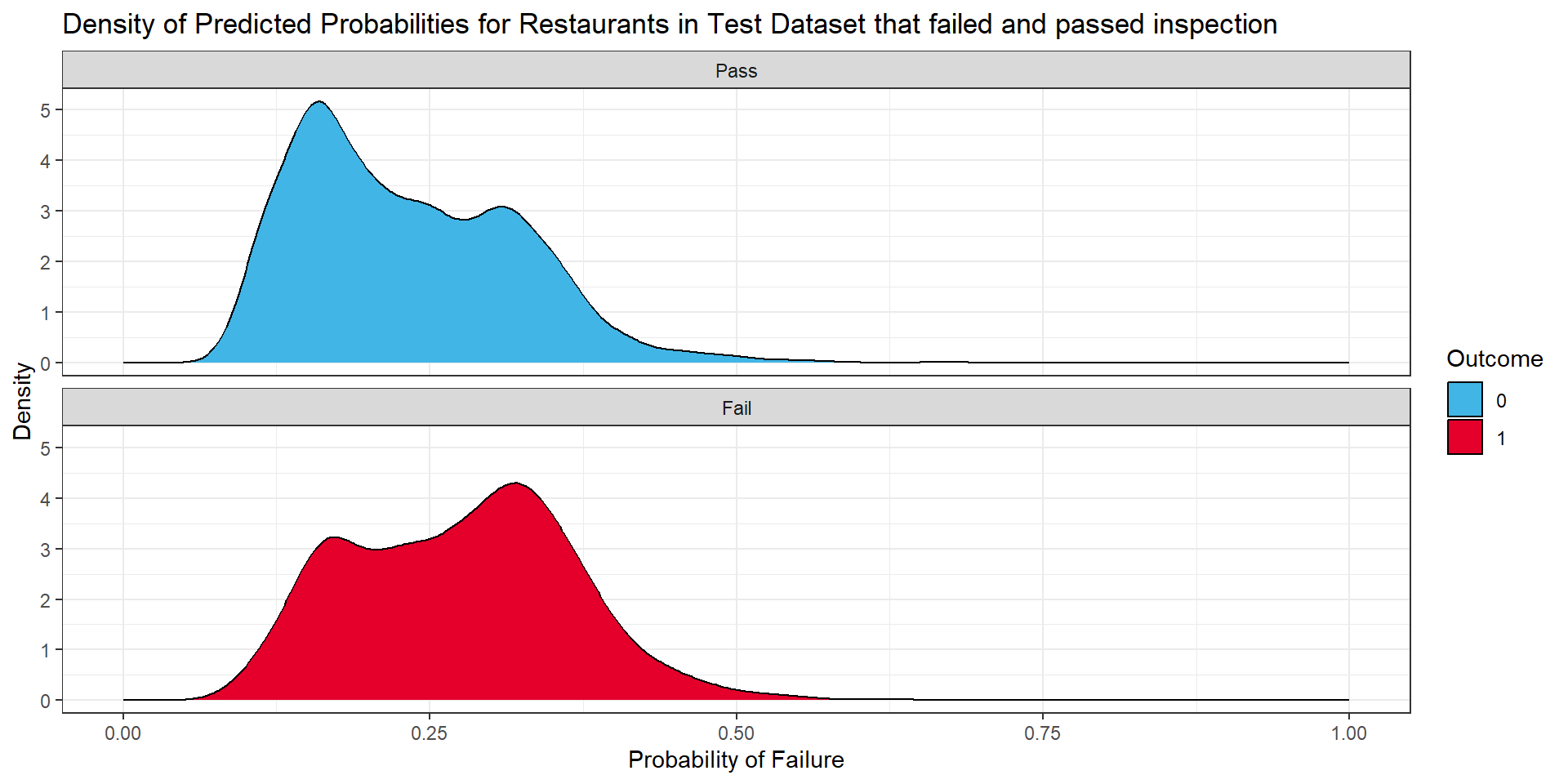
The density plots below show the density of predicted probabilities for restaurants in the test dataset that passed inspection and restaurants that failed inspections based on model three. The predicted probabilities of failing inspection for almost all points in the test dataset are under 0.50. This indicates that there is generally a high level of uncertainty on if a restaurant will pass inspection.
However, a positive sign is that the peak of the predicted probability density curve for restaurants that fail inspection is higher than for restaurants that pass inspection. The most frequent predicted fail probability for restaurants that actually failed inspection is approximately 0.3. On the other hand, the most frequent fail probability for restaurants that passed inspection is approximately 0.22.
Code
ggplot(testProbs, aes(x = probs3, fill =as.factor(Outcome))) +geom_density() +facet_wrap(~Outcome,ncol=1,labeller =as_labeller(c('0'='Pass','1'='Fail'))) +scale_fill_manual(values=c("#41B6E6","#E4002B"),name="Outcome")+scale_x_continuous(limits=c(0,1))+labs(x ="Probability of Failure", y ="Density",title ="Density of Predicted Probabilities for Restaurants in Test Dataset that failed and passed inspection") +theme(strip.text.x =element_text(size =18),legend.position ="none")+theme_bw()
The table below show the median predicted fail probability for restaurants that pass inspection and restaurants that failed inspection. The median predicted fail probability for restaurants that fail inspection is higher than restaurants that passed inspection.
A key component of using a logistic regression is selecting a threshold. Restaurants which are above this threshold are considered to have a high risk of failing inspection and would be the target of the restaurant improvement program. The table below presents three different accuracy metrics for different probability thresholds using the predictions in our test dataset.
The three accuracy measures are:
Sensitivity: The % of restaurants which are predicted to fail / The number of restaurants that actually failed
Specificity: The % of restaurants which are predicted to pass / The number of restaurants that actually passed
Accuracy: The % of restaurants which are correctly predicted / the total number of restaurants
The table below also includes the number of restaurants that are predicted to fail at each threshold (i.e: the number of restaurants with a fail probability above the threshold). We can see that there are trade offs when selecting a threshold, when using a lower threshold the specificity tends to increase while the sensitivity and accuracy decline. We choose 0.3 as the optimal threshold - at this threshold we have an accuracy rate which is still well above 50% and identify 746 restaurants as at risk of failing inspection which is a reasonable number of restaurants to target for the restaurant improvement program.
Here, we examine the confusion matrix for the test dataset predictions for our selected model (i.e: Model 3) at the selected thresholds (0.3). The confusion matrix compares our predictions to the actual outcomes. In the confusion matrix, the value in the top left corner represents cases where we correctly predicted a restaurant would pass inspection. The value in the bottom right corner indicates the number of restaurants we correctly predicted as passing inspection. The value in the top right corner, indicates the number of restaurants we predicted as Failing but actually passed inspection (i.e: false negatives). The value in the bottom left corner indicates the number of restaurants we predicted to fail that actually passed (i.e: false positives). When using the 0.3 threshold, our model miss classifies 491 restaurants as failing inspections and correctly classifies 255 restaurants resulting in a sensitivity of 34.18%.
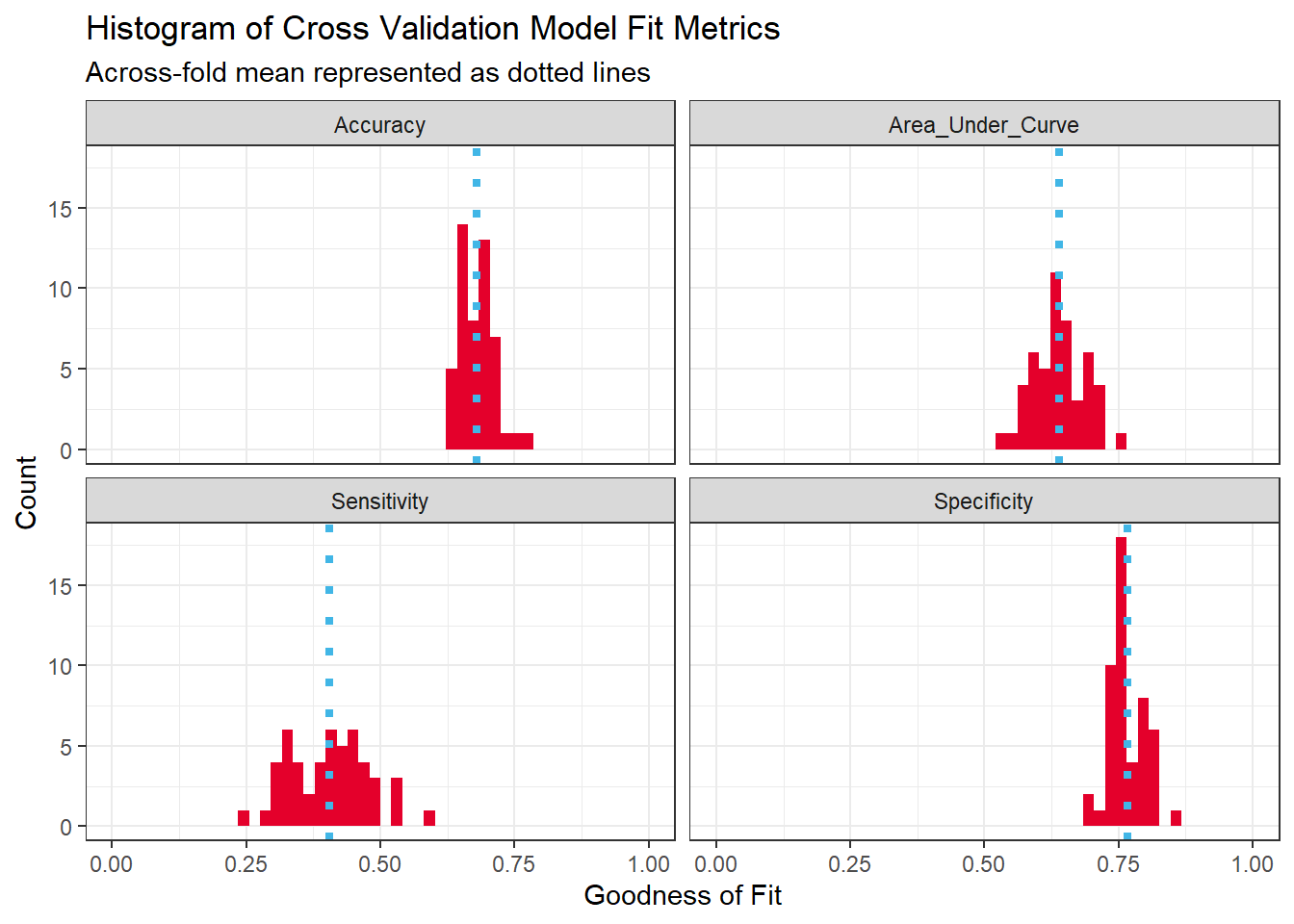
We also run a cross validation for our chosen model and threshold combination. The cross validation helps us understand if the model is generalizable to different data. A cross validation involves running the model multiple times while changing the data points which are included in the training and test datasets. We run a 50-fold cross validation using the 2021 inspection data and compare the predicted outcomes to the actual outcome in each of the 50 test datasets and calculate the sensitivity, specificty, accuracy, and area under the curve metrics for each fold.
The figure below shows the distribution of the AUC, sensitivity, specificity, and accuracy across the 50 folds. Sensitivity, specificity, and accuracy are again calculated using the 0.3 probability threshold. The model generalizes well according to the specificity and accuracy outcomes as indicated by the limited variability in the range of outcomes. However, the sensitivity (i.e: percent of failures correctly predicted) has a wider spread of outcomes across the different folds. Understanding this variation in the models ability to accurately predict restaurant failures is a key limitation which will be important for the restaurant improvement program to understand. In the next section, we will try to identify geographic areas where the model performance is poor.
Code
ctrl <-trainControl(method ="cv", number =50, classProbs =TRUE, savePredictions =TRUE, summaryFunction = twoClassSummary)cvFit <-train( results ~ age + prev_fails + Median_Rent + rodents.nn + sanitation.nn + thefts.nn + risk + pct_poverty + prev_year_pct_fail + decile + risk,data = data_2021_2,method ="glm",family ="binomial",metric ="ROC",trControl = ctrl)#This is doing the cross validation with a custom threshold, using a treshold of 0.5 is not useful and could not figure out how to use a different threshold with the summaryFunctionpred <- cvFit$pred %>%mutate(pred = (ifelse(Fail >0.30,'Fail','Pass')),type =case_when(pred =='Fail'& obs =='Fail'~'TP', pred =='Pass'& obs =='Pass'~'TN', pred =='Fail'& obs =='Pass'~'FP', pred =='Pass'& obs =='Fail'~'FN')) %>%group_by(Resample,type) %>% tally %>%spread(key=type,value=n) %>%mutate(Sensitivity = TP / (TP + FN),Specificity = TN / (FP + TN),Accuracy = (TP + TN) / (TP + TN + FP + FN)) %>%inner_join(.,cvFit$resample %>% dplyr::select(Resample,ROC),by='Resample') %>% dplyr::select('Sensitivity','Specificity','Accuracy','ROC') %>%rename(Area_Under_Curve ='ROC') %>%pivot_longer(cols=c('Sensitivity','Specificity','Accuracy','Area_Under_Curve'),names_to='metric',values_to='value') %>%group_by(metric) %>%mutate(mean =mean(value))ggplot(data=pred,aes(value)) +geom_histogram(bins=50, fill ='#E4002B')+facet_wrap(~metric) +geom_vline(aes(xintercept = mean), colour ="#41B6E6", linetype =3, size =1.5) +scale_x_continuous(limits =c(0, 1)) +labs(x="Goodness of Fit", y="Count", title="Histogram of Cross Validation Model Fit Metrics",subtitle ="Across-fold mean represented as dotted lines")+theme_bw()
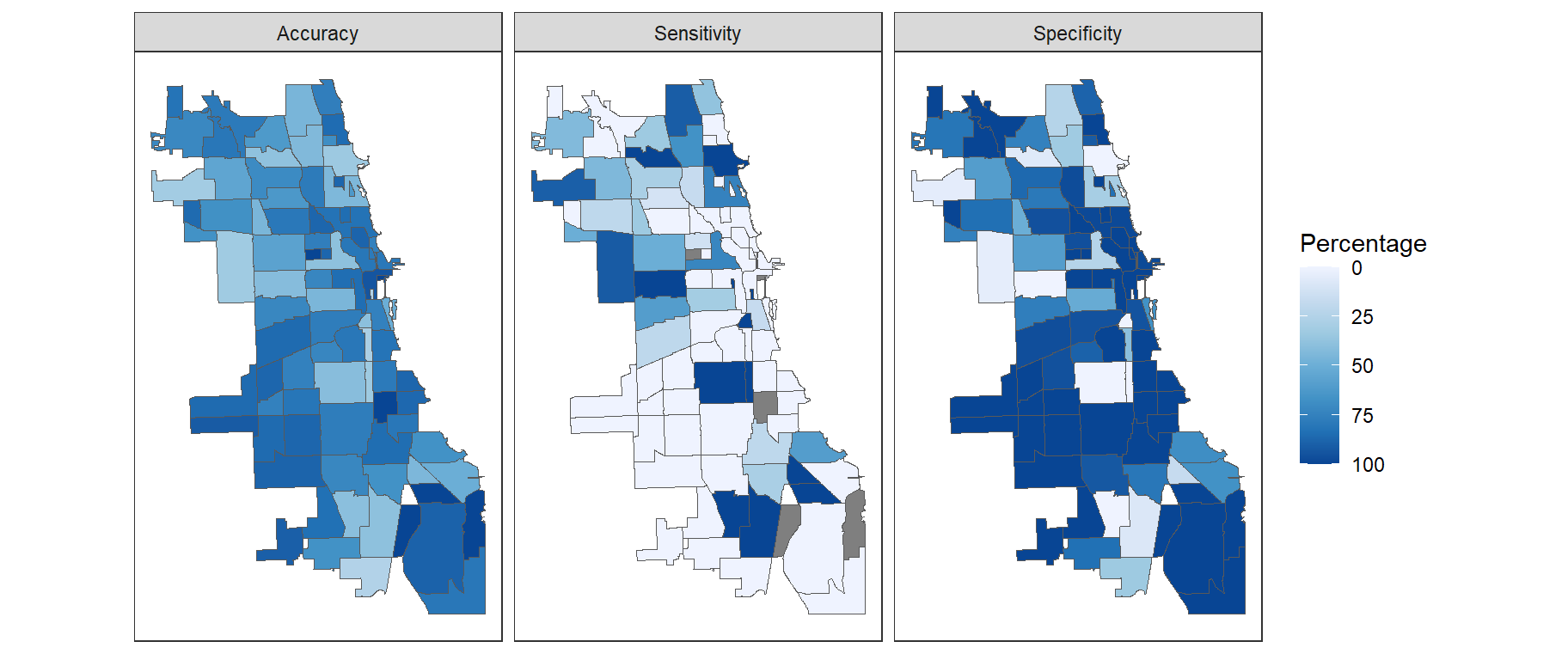
Accuracy by Neighboorhood
The maps below show the sensitivity, specificity, and accuracy of the model predictions for the initial test dataset by neighborhood when using the 0.3 threshold. There are some key spatial patterns and trends in the results which are important for model users to understand. First, the sensitivity in many neighborhoods is 0%. This means that in many parts of the city the model failed to accurately predict all restaurant failures when setting the threshold for a predicted failure at 0.3. Examples of neighborhoods where this is true include Grand Boulevard, United Center, Armour Square and Logan Square. The neighborhoods which have a sensitivity of 0% tend to also have a specificity near 100%.
Conversely, there are also neighborhoods where the specificity is 0% and the sensitivity is near 100%. Examples of such neighborhoods include Chinatown, New City, Garfield Park and Washington Heights. These are the same neighborhoods which had high failure rates based on our exploratory analysis.
To better understand how sensitivity, specificity, and accuracy vary across different types of neighborhoods we group all neighborhoods in Chicago into four categories based on the restaurant inspection failure rate for restaurants in 2021. Each category contains the same number of neighborhoods.
Our predictions for restaurants in neighborhoods that have a very low or low historical failure rate exhibit a low sensitivity, high specificity, and high overall accuracy. The low sensitivity indicates that our model only accurately predicts 1.6% of restaurant failures in neighborhoods with a low historical failures. Because the number of failures is very small (approximately 8-12% of inspections in most neighborhoods) our accuracy is still high in these neighborhoods.
Our predictions for restaurants in neighborhoods that have a high historical failure rate exhibit a high sensitivity and low specificity, and low overall accuracy. The low specificity indicates that our model only accurately predicts 21.71% of restaurants as passing inspections. A large number of restaurants that actually passed inspections are miss classified as failing inspections in neighborhoods with a high historical failure rate.
We also examine our model performance across different race contexts. We classify census tracts into majority white census tracts and majority non white census tracts and examine the accuracy, sensitivity, and specificity for predictions for restaurants in majority white and majority non white census tracts using our selected threshold of 0.3. The sensitivity is higher for restaurants in majority non-white areas and the specificity is lower. The lower specificity our model and threshold combination tends to overestimate the number of restaurant failures in non-white areas. Conversely, the low sensitivity in white areas indicates that the model misses a large percentage of restaurant failures in majority white area.
Overall we conclude that our model will help the city of Chicago identify locations for the restaurant improvement program, but should not be the only piece of information city decision makers rely on. We recommend that future work focus on selecting different optimized probability thresholds by neighborhood. In neighborhoods like Chinatown which have a high historical failure rate, it may make sense to select a threshold higher than 0.3. However, in neighborhoods that have a low historical failure rate, it may be appropriate to select a threshold that is lower than 0.3.
Additionally, a noted limitation of our model is that it is focused on spatial features. Unfortunately, limited data is available on internal characteristics of restaurants and its staff - data on these features could help improve the model. Examples of predictors that might help improve the model include square footage, kitchen size, number of customers, number of kitchen staff, and if the head chief attended culinary school. Access to this type of data could help improve the model and provide additional predictive power and will help better capture the non spatial drivers of restaurants failing inspections. In the absence of such data, one potential dataset which could be incorporated into the model is data from Yelp. Examples of variables from Yelp that could be incorporated include the number of stars the restaurant has and the type of restaurant - preliminary analysis conducted by Michael Duchak indicates that both these variables could help predict restaurant failures in Chicago.
In terms of next steps, we recommend starting discussions with a software developer about exploring ways to show the model results in an interactive application. Additionally, the modeling team would like to explore developing optimized probability threshold cutoffs for each neighborhood while also exploring the possibility of incorporating data from Yelp into the model. The final model would then be used to predict restaurant failures in 2024, and data from 2023 should be used for the k nearest neighbor analysis and identifying the percent of restaurants within 1 kilometer that failed in the previous year. The predictions for 2024 could then help city decision makers decide what restaurants to target for the restaurant improvement program.