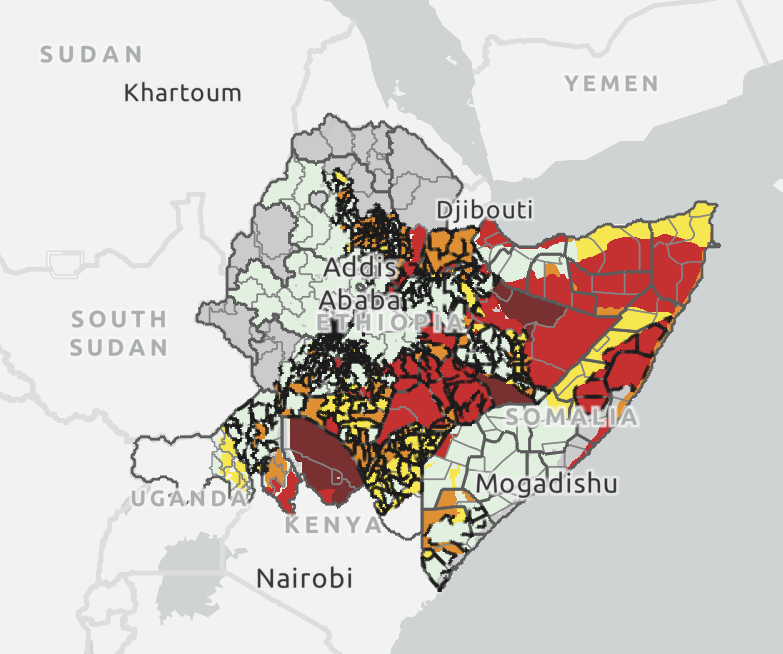
The Global Dashboard for Hotspot Identification (GDHI) is a screening tool used for by the Famine Early Warning System Network to identify potential food security areas of concern in the Horn of Africa. The GDHI provides FEWS NET with a rough estimate of potential food security durring the upcoming year. In my role as a Livelihood Monitoring Analyst at FEWS NET I was responsible for helping to build and run the GDHI on a monthly basis. The GDHI was developed as an Excel based tool, and historically analysts had to review the results of the analysis by e-mailing an Excel file with the results to everyone who needed them. In order to make the results more accessible I set-up a data visualization system to display the results using Microsoft Power BI and ArcGIS Online. Additionally, I developed a Python script that reads the results from an Excel file, transforms the results into the formats needed by Power BI and ArcGIS Online, and publishes the results. Browse below to view the python script, ArcGIS Online Maps, and Power BI Dashboard. Links to view the Power BI Dashboard and ArcGIS Online Maps in full screen are available above.
A link to a video overview of the GDHI is also included above. Please watch the video if you are interested in learning more about how the GDHI works and how FEWS NET uses the map and dashboard tools I created.
Python Script
The script below was written to automate the process of publishing the GDHI results to Power BI and ArcGIS Online. The script is written using arcpy, pandas, and datetime libraries and includes the following steps:
Update the ArcGIS Online Feature class
Extracts the GDHI results from excel file and imports the results to Pandas Dataframe.
Merge together the Ethiopia results with the Kenya, Uganda, and Somalia GDHI results - Ethiopia results are stored in a separate file.
Exports pandas data frame to a .csv file, join .csv to a feature class, and export the joined result.
Sets appropriate aliases for the feature class fields
Add feature class to a Pro project, and remove feature class from previous month
Publish updated ArcGIS Pro map to ArcGIS Online
Update the csv files used in the Power BI Dashboard:
Get current outlook and year from Excel Interface file
Create a dictionary with the time range associated with each analysis quarter based on the selected outlook and year run
Flatten results using Pandas to create a flat file on population by Phase, by quarter for each area of analysis - export CSV results
Flatten results using Pandas to create a flat file on MT needs by quarter for ach area of analysis - export CSV results
Click the code button bellow to view the full script!
Code
import osimport pandas as pdimport datetimefrom dateutil.relativedelta import relativedeltaimport arcpyimport openpyxlfrom arcgis.gis import GISarcpy.env.overwriteOutput =True#This is the directory where the GDHI files for the current month are savedKE_SO_UG_GDHI=r'C:\Users\rbarad\OneDrive - Chemonics\10.GDHI\01.EA_Monthly_Runs\02.GDHI-tool\2023\05_RB\KE_UG_SO\run2'#Path to GDHI Excel files for KE, UG, SO for 2nd runET_GDHI=r'C:\Users\rbarad\OneDrive - Chemonics\10.GDHI\01.EA_Monthly_Runs\02.GDHI-tool\2023\05_RB\ET\GDHI_Outlook'#Path to GDHI results files for ETET_GDHI_NOPSNP='NatLIAS_res_summ_Outlook_NOPSNP.xlsm'#Name of results file without PSNPET_GDHI_PSNP='NatLIAS_res_summ_Outlook.xlsm'#Name of results file with PSNP#Edit this to select when adminstrative areas in Ethiopia should be greyed outadmin2_units = ['Zone 1','Zone 2','Zone 4','North Gondar', 'Wag Himra', 'North Wollo'] #Must match spelling used in shapefileadmin1_units = ['Tigray'] #Must match spelling used in shapefile, if you want to exclude an entire admin1 unit specify it here#Set month and year when analysis is formonth=5year=2023params= {'input_featureclass':'SO_UG_KE_ET_GDHI_Admin_LHZ_simp', #Name of Feature class to join GDHI results to - must be stored in Pro Project GDB which is specified as the arcpy.env.workspace'sharepoint_folder':r'C:\Users\rbarad\OneDrive - Chemonics\10.GDHI\01.EA_Monthly_Runs\01.SharePoint', #Location of Share Point folder containing ArcGIS Pro Project and Power BI Files'username':'XXXX', #username for AGOL'password':'XXXXXX', #Password goes here'service':'GDHI_results'} #Name of service in AGOL to overwriteoutlookstart = {1: 1,2: 4,3: 10}#Set the file path to the sharepoint folder, Project GDB, and Pro Projectsharepoint_folder = params['sharepoint_folder']arcpy.env.workspace=os.path.join(sharepoint_folder,'GDHI_Results.gdb') #Set arcgis workspacepro_project = os.path.join(sharepoint_folder,'GDHI_Results.aprx') #Set path to project#Dictionary Contains Aliases to assign to each column in the feature classalias_list= {'Q1_IPC_Max': 'Q1 Max Indicative Household Phase','Q1_IPC_Area': 'Q1 Indicative Area Phase','Q1_3plus': 'Q1 Pop in IPC Phase 3+','Q1_MT': 'Q1 Metric Tons of aid','Q2_IPC_Max': 'Q2 Max Indicative Household Phase','Q2_IPC_Area': 'Q2 Indicative Area Phase','Q2_3plus': 'Q2 Pop in IPC Phase 3+','Q2_MT': 'Q2 Metric Tons of aid','Q3_IPC_Max': 'Q3 Max Indicative Household Phase','Q3_IPC_Area': 'Q3 Indicative Area Phase','Q3_3plus': 'Q3 Pop in IPC Phase 3+', 'Q3_MT': 'Q3 Metric Tons of aid','IPC_Max': 'Highest Indicative Household Phase','IPC_Area_Max':'Highest Indicative Area Phase', 'IPC_Area_Avg': 'Average Indicative Phase','MT_Total': 'Total Metric tons (Q1 - Q3)','Total_pop':'Total Population','Kg_Per_capita':'Kilograms per capita'}#Class of functions to read results into a pandas dataframesclass read_merge_data():def read_ke_so_ug(kesoug_results):print('Read KE,SO,UG Results Data') os.chdir(kesoug_results) results = pd.DataFrame(pd.read_excel('NatLIAS_res_summ.xlsx',sheet_name='Mapping',skiprows=1,nrows=311)) #Read results from GDHI into a Dataframereturn resultsdef read_et(et_folder,filename):print('Read ET Results Data') os.chdir(et_folder) results = pd.DataFrame(pd.read_excel(filename,sheet_name='Mapping_Meth2',skiprows=1,nrows=875)) #Read results from GDHI into a Dataframe results=results[results['FNID'].notnull()] results = results[~((results['Admin2'].isin(admin2_units)) | (results['Admin1'].isin(admin1_units)))] #Remove Zone 1, Zone 2, and Zone 4 of Afar and Tigray since GDHI Not Valid there results['COUNTRY'] ='Ethiopia'return resultsdef merge(kesoug_results,et_folder,et_filename): results1 = read_merge_data.read_ke_so_ug(kesoug_results) results2 = read_merge_data.read_et(et_folder,et_filename)print('Merge Data') results = pd.concat([results1,results2],ignore_index=True)return resultsresults = read_merge_data.merge(KE_SO_UG_GDHI,ET_GDHI,ET_GDHI_PSNP) #Read results with PSNPresults_NOPSNP = read_merge_data.read_et(ET_GDHI,ET_GDHI_NOPSNP) #Read results without PSNPdef create_quarter_IPC_list(): #Function creates a list of collumns names for the combinations of IPC Phases and quarter (i.e: Q1_IPC1, Q1_IPC2, Q1_IPC3, Q1_IPC4, Q1_IPC5, Q2_IPC1, etc.) quarters=['Q1','Q2','Q3'] quarters_phase_list = [] IPC_Phase =range(1,6)for q in quarters:for p in IPC_Phase: quarter_phase = q +'_IPC'+str(p) quarters_phase_list.append(quarter_phase)return quarters_phase_listdef create_quarter_variable_list(): #Function create list of data column names for each quarter - includes MT per quarter, Area Phase Clasification, Highest Phase Classification, and Metric Tons (MT) quarters=['Q1','Q2','Q3'] fields = ['IPC_Max','IPC_Area','3plus','MT'] quarter_field_list = []for q in quarters:for f in fields: field = q +"_"+ f quarter_field_list.append(field)return quarter_field_listdef create_results_featureclass(df,output_name): #Function to create featureclass, 1st input is a df containing GDHI results, second input is name of output featureclassprint("Create Featureclass for GDHI results...")#Save copy of GDHI Mapping units in memory gdhi_shapes = os.path.join('in_memory',params['input_featureclass']) arcpy.management.CopyFeatures(params["input_featureclass"], gdhi_shapes) #Create copy of GDHI shapes in-memory#Convert GDHI results to a .csv and join results to in memory featureclass, export featureclass to disk, delete .csv once complete df.to_csv('NATLIAS_results.csv') results_csv= os.getcwd() + os.sep +"NATLIAS_results.csv" results_table = arcpy.conversion.TableToTable(results_csv, arcpy.env.workspace, 'results') #Had to convert csv to a table because JoinField Function was not working with .csv in Pro 3.0. arcpy.JoinField_management(gdhi_shapes, 'FNID', results_table, 'FNID',fields_join) #Append data to in-memory featureclass arcpy.management.CopyFeatures(gdhi_shapes, output_name) arcpy.Delete_management("results") os.remove(results_csv)def set_aliases(output): #Set aliasesfor field in fields_join:print("Update Alias for "+ field) arcpy.AlterField_management(output, field, new_field_alias=alias_list[field])#Create featureclass for ESRI story map with & without PSNP using defined functionsfields_join = create_quarter_variable_list() + ['IPC_Max','IPC_Area_Max','IPC_Area_Avg','MT_Total','Total_pop','Kg_Per_capita'] #Create list of quarterly data fields using function and add average variables to listmonth_name = datetime.date(year, month, 1).strftime('%Y_%m') #Create string based on month and year to use in featureclass namesoutput_name ='GDHI_results_'+ month_name #Set name of output feature class with PSNPcreate_results_featureclass(results,output_name) #Create feature class for results with PSNPset_aliases(output_name) #Set alias names in feature classoutput_name_NOPSNP ='GDHI_results_'+ month_name +'NOPSNP'#Set name of output feature class without PSNPcreate_results_featureclass(results_NOPSNP,output_name_NOPSNP) #Create feature class for results without PSNPset_aliases(output_name_NOPSNP) #Set alias names in feature class#Create variables for Pro Project and Map in Pro Projectaprx = arcpy.mp.ArcGISProject(pro_project)aprxMap = aprx.listMaps("Map")[0] def update_pro_project():#Add new results Featureclasses to the ArcGIS Pro Project - rename layers, but first remove old GDHI results layer from map so that map only includes one layer.print("Update Pro Project...") lyr_path_PSNP = os.path.join(arcpy.env.workspace,output_name) lyr_path_noPSNP = os.path.join(arcpy.env.workspace,output_name_NOPSNP)for lyr in aprxMap.listLayers(): #Remove existing layers aprxMap.removeLayer(lyr) aprxMap.addDataFromPath(lyr_path_PSNP) #Add layer lyr = aprxMap.listLayers()[0] #Select first and only layer in map lyr.name ='GDHI_results'#Rename selected layer to 'GDHI_results' aprxMap.addDataFromPath(lyr_path_noPSNP) #Add no PSNP Layer to map move_lyr = aprxMap.listLayers('*PSNP')[0] #Select no PSNP layer aprxMap.moveLayer(lyr, move_lyr, 'AFTER') #Move PSNP to be the second layer in map to keep same order move_lyr.name ='GDHI_results_NOPSNP'#Rename selected layer to 'GDHI_results_NOPSNP' to keep name the same aprx.save()print("Pro Project Updated")def update_AGOL():#Sign in to ArcGIS Onlineprint("Sign in to ArcGIS Online") gis = GIS('https://www.arcgis.com', params['username'], params['password'])# Set sharing draft and service definition file names service = params['service'] sddraft_filename = os.path.join(sharepoint_folder, service +".sddraft") sd_filename = os.path.join(sharepoint_folder, service +".sd")# Create FeatureSharingDraft and set service propertiesprint("Create Sharing Draft and Service Defintion Files...") sharing_draft = aprxMap.getWebLayerSharingDraft("HOSTING_SERVER", "FEATURE", service) sharing_draft.summary ="Results of the GDHI for "+ datetime.date(year, month, 1).strftime('%B %Y') sharing_draft.overwriteExistingService =True sharing_draft.portalFolder ='01. GDHI'# Create Service Definition Draft file and service definition sharing_draft.exportToSDDraft(sddraft_filename) arcpy.StageService_server(sddraft_filename, sd_filename)# Find the Service definition, update it, publish /w overwrite and set sharing and metadataprint("Search for original SD on portal…") searchData = gis.content.search(query="title:"+ service +" AND owner: "+'FEWS_NET', item_type="Service Definition")for search in searchData:print(search)if search.title== service:print("Found SD: {}, ID: {} Uploading and overwriting…".format(search.title, search.id)) search.update(data=sd_filename)print("Overwriting existing feature service…") fs = search.publish(overwrite=True)print("Finished updating: {} – ID: {}".format(fs.title, fs.id))else: passprint('Pass item in list')#Update Pro project and publish feature class to AGOL.update_pro_project()update_AGOL()#arcpy.Delete_management("in_memory") #Clear arcgis memory space#Rest of script creates csv files which are used in Power Bi. Will need to open Power BI and update data source after script copmletesdef get_outlook_year_from_Excel(): #Get the outlook and year of analysis from the SO, UG, KE GDHI file. os.chdir(KE_SO_UG_GDHI) book = openpyxl.load_workbook('NatLIAS_interface.xlsm') sheet = book.active year = sheet['E9'].value outlook = sheet['E7'].valuereturn[year,outlook]def generate_ranges(): #Generate month ranges for each quarter and write results to a python dictionary, subsequently used in IPC_Phase_Clean() and IPC_MT_Clean() functions to get the month ranges for eqch quarter dictionary = {} print ("Gernerate date range for each quarter, based on selected outlook") date = get_outlook_year_from_Excel() start_date= datetime.date(date[0], outlookstart[date[1]], 1) #Convert number representing month from outlook start to a date based on year, and start month of selected GDHI run dictionary['Q1']='('+ start_date.strftime("%b. %y") +' - '+ (start_date + relativedelta(months=2)).strftime("%b. %y") +')' dictionary['Q2']='('+ (start_date + relativedelta(months=3)).strftime("%b. %y") +' - '+ (start_date + relativedelta(months=5)).strftime("%b. %y") +')' dictionary['Q3']='('+ (start_date + relativedelta(months=6)).strftime("%b. %y") +' - '+ (start_date + relativedelta(months=8)).strftime("%b. %y") +')'return dictionarydef IPC_Phase_Clean(df,output_name): #Flatten to create a file on population by Phase, per quarterprint("Create File for IPC Phase by Quarter")try: #This try logic is necessary because the data with PSNP does not include an LH Zone Column since it just for Ethiopia df_filt = df[~df['LH Zone'].isin(['BDA','SO19','KMO'])] #Remove urban results (only needed for results with Somalia included) results_org = df_filt.melt(id_vars=['FNID','COUNTRY','Admin1','Admin2','Admin3','LH Zone','Total_pop'],value_vars=create_quarter_IPC_list(),value_name='Pop',var_name='Quarter_Phase') except: results_org = df.melt(id_vars=['FNID','COUNTRY','Admin1','Admin2','Admin3','Total_pop'],value_vars=create_quarter_IPC_list(),value_name='Pop',var_name='Quarter_Phase') results_org['Quarter'] = results_org['Quarter_Phase'].str.split("_",n =1, expand =True)[0] results_org['Phase'] = results_org['Quarter_Phase'].str.split("_",n =1, expand =True)[1] results_org['Quarter'] = results_org['Quarter'] +' '+ results_org['Quarter'].map(quartertimeranges) results_org['Pop'] = results_org['Pop'].round(0) #round to nearest whole person since you can not have half a person results_org.drop(labels='Quarter_Phase',axis=1,inplace=True)try: results_org.sort_values(['COUNTRY','Admin1','Admin2','Admin3','LH Zone','Quarter','Phase'],inplace=True)except: results_org.sort_values(['COUNTRY','Admin1','Admin2','Admin3','Quarter','Phase'],inplace=True) results_org.to_csv(output_name)def IPC_MT_Clean(df,output_name): #Flatten to create a file on MT by quarterprint("Create File for MT Needs by Quarter")try: #This try logic is necessary because the data with PSNP does not include an LH Zone Column since it just for Ethiopia df_filt = df[~df['LH Zone'].isin(['BDA','SO19','KMO'])] #Remove urban results (only needed for results with Somalia included) results_org_MT = df_filt.melt(id_vars=['FNID','COUNTRY','Admin1','Admin2','Admin3','LH Zone','Total_pop'],value_vars=['Q1_MT','Q2_MT','Q3_MT'],value_name='MT',var_name='Quarter_MT')except: results_org_MT = df.melt(id_vars=['FNID','COUNTRY','Admin1','Admin2','Admin3','Total_pop'],value_vars=['Q1_MT','Q2_MT','Q3_MT'],value_name='MT',var_name='Quarter_MT') results_org_MT['Quarter'] = results_org_MT['Quarter_MT'].str.split("_",n =1, expand =True)[0] results_org_MT['Quarter_detail'] = results_org_MT['Quarter'] +' '+ results_org_MT['Quarter'].map(quartertimeranges) results_org_MT.drop(labels='Quarter_MT',axis=1,inplace=True)try: #This try logic is necessary because the data with PSNP does not include an LH Zone Column since it just for Ethiopia results_org_MT.sort_values(['COUNTRY','Admin1','Admin2','Admin3','LH Zone','Quarter',],inplace=True)except: results_org_MT.sort_values(['COUNTRY','Admin1','Admin2','Admin3','Quarter',],inplace=True) results_org_MT.to_csv(output_name)#Create csv files for PowerBI - save to Sharepoint folderquartertimeranges = generate_ranges()os.chdir(sharepoint_folder) # Change directory to SharePoint folder so that csv files are exported here - same path to csv file each time#Create Power BI files for results with PSNPIPC_Phase_Clean(results,'IPC_Phase.csv')IPC_MT_Clean(results,'MT_Needs.csv')#Create PowerBI files for results without PSNPIPC_Phase_Clean(results_NOPSNP,'IPC_Phase_noPSNP.csv')IPC_MT_Clean(results_NOPSNP,'MT_Needs_noPSNP.csv')print("Script Complete")
ArcGIS Online Maps
The maps below are created in ArcGIS Online to help showcase the results of the GDHI. The included maps show the highest indicative IPC Phase and the highest Indicative Household IPC Phase estimated by the GDHI across the analysis period. There is also a map showing the total Metric Tons of Assistance needed to fill deficits across the analysis period. The maps are combined into a single application using instant app tools available in ArcGIS Online. Click on the arrows at the bottom of the page to toggle between the different available maps.
Power BI Dashboard
I created the Power BI Dashboard below to show the results of the GDHI Analysis. The Dashboard provides information on the estimated population in each IPC Phase and includes visualizations showing the average population in IPC Phase 2+ by administrative unit across the period of analysis. The dashboard also provides information on the estimate Metric Tons of food assistance needed to fill food security deficits by quarter. You can click on the arrows at the bottom of the dashboard to see results for different countries.